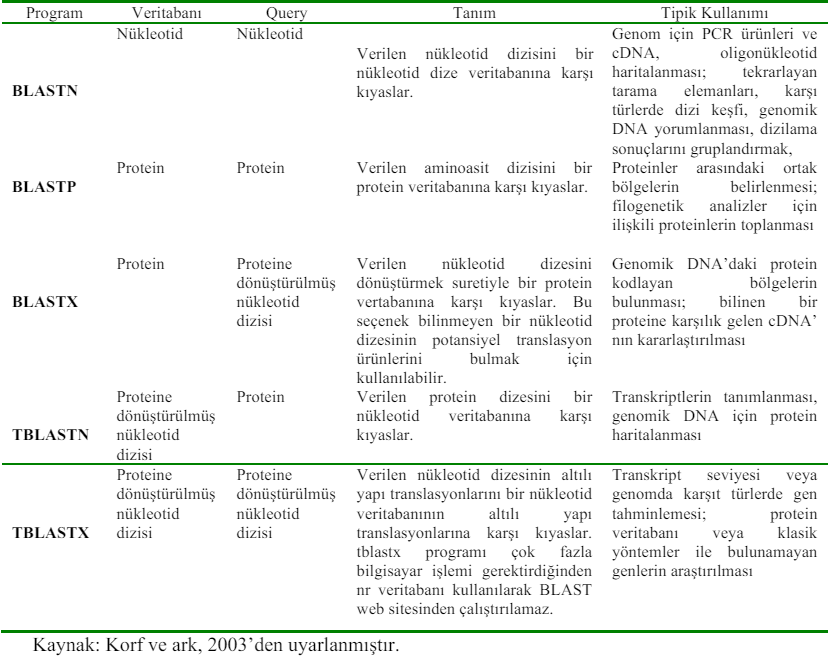
Accession number (GenBank): Bir dizi GenBank’a kaydedildiği zaman bu kayıt için
verilen ve kayda özel kimlik numarasıdır. Bir büyük harf ve ardından gelen 5 rakam veya 2
büyük harf ve 6 rakamdan oluşur. Girilen dizi ile ilgili bilgilerin güncellenmesi durumunda
dahi hiçbir şekilde değiştirilmez.
Accession number (RefSeq): Bütün bir RefSeq dizisine atanmış kimlik numaralarıdır.
Sırasıyla iki büyük harf, bir alt çizgi (_) ve 6 rakamdan oluşur (ör: NT_123456). İlk iki rakam
dizi tipini gösterir:
- NT_123456 birleştirilmiş genomik kontigler
- NM_123456 mRNA’lar (mRNA’dan oluşturulmuş cDNA’lar)
- NP_123456 proteinler
- NC_123456 kromozomlar
Bit score: Kullanılan skorlama sisteminin istatistiksel özelliklerinin hesaba katılmasıyla ham
karşılaştırma skoru S’ten türetilmiş S değeridir. Skorlama sistemine göre normalize edilmiş
değerler olduklarından farklı karşılaştırmalar arasında ilişki kurmak için kullanılabilirler.BLAST (Basic Local
Alignment Search Tool): Aynı ya da farklı organizmalar arasında
nükleotid ya da protein dizisi karşılaştırılması ve benzer bölgelerin araştırılması için
kullanılan yüksek hızda bir bilgisayar programıdır.
Blosum (block substitution matrix): Proteinlerin karşılaştırılması ile elde edilen blokların
değişim frekansının gözlemlesinden türetilmiş değerlerden oluşan bir değişim matrisidir. Her
matris özel bir evrimsel uzaklığa uyarlanır.
CDS: Bir nükleotid dizisinin kodonları oluşturan bölgesi ya da kodlayan dizi.
Conserved sequence (korunmuş dizi): Bir DNA moleklünde (bir proteindeki aminoasi dizisinde) evrim sürecinde değişmeden kalmış olan baz dizisi.
Contig: Bir kromozomun üst üste çakışma gösteren, klonlanmış farklı DNA parçaları grubu.
Domain: Bir proteinin bağımsız olarak katlanabildiği ve çalışabildiği kabul edilen parçası.
E value (expectation value): Beklenti değeri. Veritabanı taramasında şans eseri çıkması beklenen, S değerine denk ya da daha büyük skorlara sahip benzer dizilerin sayısı. Düşük E değeri büyük skora işaret eder.
EST (expressed sequence tag): Bir cDNA molekülünün, bir genin kimliği olarak kullanılabilecek kısa bir parçası. Genlerin konumlanmasında ve haritalanmasında kullanılır.
Homologue: Dizisi büyük oranda başka bir gene benzeyen gen. Bu genlerin ortak bir ataya
sahip olduğu ve benzer fonkiyonlar taşıdığı düşünülür.
Motif: Protein dizisi içinde kısa, korunmuş bir bölge. Motifler genellikle domainlerin yüksek
derecede korunmuş bölgeleridir.
Orthologous: Ortak bir atadan geldikleri düşünülen, benzer bir fonksiyonu olabilen, farklı
türlere ait homolog dizilerdir.
Paralogous: Aynı tür içinde, gen duplikasyonu sonucu oluşmuş homolog diziler.
Query: Veritabanındaki tüm dizilerin karşılaştırılacağı giriş dizisidir.
Kaynak: Kaya ve ark. ‘t.y.’