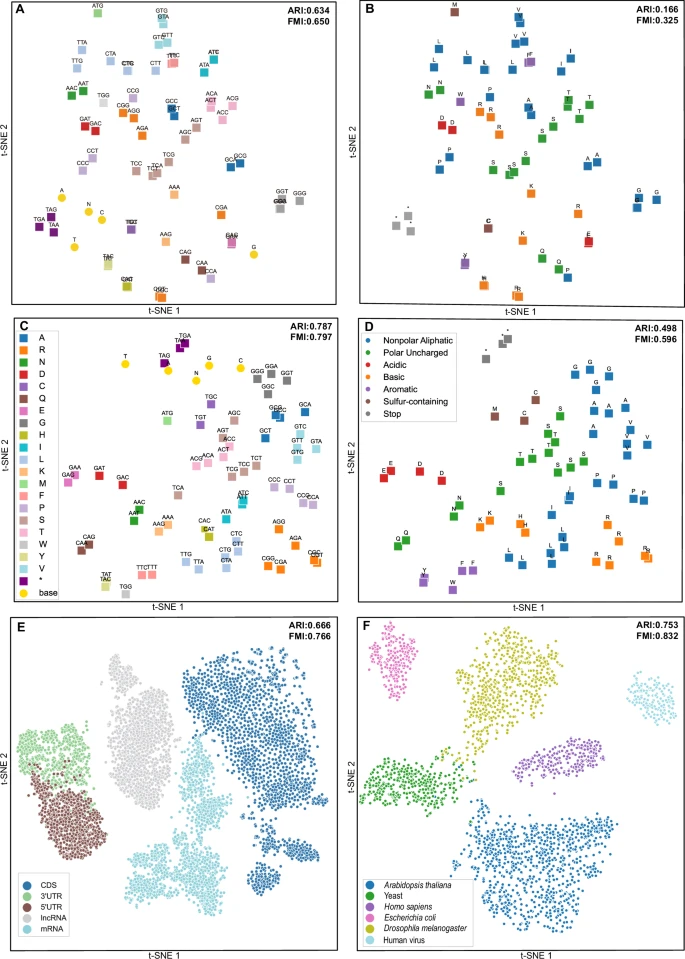
Biyomedikal veri artırma için yapay zekanın kullanılması: model özelliklerinin, performans analizinin ve gelecekteki araştırma yönlerinin karşılaştırmalı incelemesi için yorumlar kapalıteknoloji
Soyut
Yapay Zeka (YZ), sağlık sektörü de dahil olmak üzere çeşitli sektörlerde üretkenliği, verimliliği ve etkinliği artıran günümüzün en gelişmiş teknolojilerinden biridir. Ancak bu üretkenliğin tanımlanması, müdahale alanında veri kullanılabilirliğini gerektirir. Potansiyeline karşın, sağlık sektörü inovasyonu için biyomedikal veriler, gizlilik endişeleri nedeniyle erişilmesi en zor verilerden biridir. Bu zorluğun üstesinden gelmenin yollarından biri, sağlık sektörü üretkenliğinde devrim yaratma potansiyeline sahip olan “Verileri Artırmak” için YZ’nin kullanılmasıdır. Bu araştırma makalesi, biyomedikal veriler için Veri Artırma (DA) üzerine kapsamlı bir inceleme sunmakta olup, özellikle Üretken Çelişkili Ağ (GAN) odaklı öğrenme yöntemlerine odaklanmaktadır. Veri Artırma yöntemlerini, bu yöntemlerin özellikleri, üretilen verilerin kalitesini değerlendirmek için kullanılan performans ölçütleri ve her yöntemin sınırlamaları açısından analiz etmektedir. Ayrıca, bu çalışma, GAN’ların ve Koşullu GAN’ların (CGAN’lar) performansını, özellikler ve performans ölçütlerini içeren iki farklı bakış açısıyla farklı veri kaynakları ve boyutları üzerinde değerlendirmek için kapsamlı bir deneysel analiz içermektedir. Sonuç olarak, mevcut GAN’ların ve GAN’ların değiştirilmiş versiyonlarının analizi, biyomedikal uygulamalarda üretken modellerin kullanımında önemli bir potansiyel olduğunu göstermektedir. Bu araştırmadan elde edilen temel bulgular, güvenilir artırılmış verilere ulaşmada iki temel zorluğu ortaya koymaktadır: a) GAN modelleri için kararsız eğitim ve b) daha güvenilir değerlendirme ölçütlerine duyulan ihtiyaç. Bu zorlukların ele alınması, minimum eğitim verisi ve öğrenme yinelemeleriyle güvenilir DA tekniklerini garanti altına alabilen yeni nesil GAN modelleri geliştirmek için hayati önem taşıyacaktır.
mRNABERT: Evrensel bir dil modeli ve kapsamlı veri setiyle mRNA dizi tasarımını ilerletmek için yorumlar kapalıBİLİM
Terapötikler için etkili mRNA dizileri tasarlamak zorlu bir görev olmaya devam etmektedir. Protein tasarımındaki başarılardan ilham alan dil modelleri (LM’ler) artık RNA’ya da uygulanıyor, ancak kapsamlı eğitim verilerinin eksikliği ilerlemeyi genellikle engelliyor. Mevcut modeller genellikle UTR veya CDS bölgeleriyle sınırlı olduğundan, tam mRNA dizileri için uygulamaları kısıtlanıyor. Mevcut en büyük mRNA veri kümesi üzerinde önceden eğitilmiş, sağlam ve hepsi bir arada bir mRNA tasarımcısı olan mRNABERT’i tanıtıyoruz. Performansı artırmak için, protein dizilerinden gelen anlamsal bilgileri entegre etmek üzere çapraz-modaliteli karşılaştırmalı bir öğrenme çerçevesine sahip ikili bir belirteçleme şeması öneriyoruz. Kapsamlı bir kıyaslamada, mRNABERT, 5′ UTR ve CDS tasarımı, RNA bağlayıcı protein (RBP) bölgesi tahmini ve tam uzunlukta mRNA özelliği tahmini görevlerinin çoğunda önceki modellerden daha iyi performans göstererek en son teknolojiyi göstermektedir. Ayrıca, çeşitli ilgili görevlerde büyük protein modellerini de geride bırakmaktadır. Sonuç olarak, mRNABERT’in bu çeşitli görevlerdeki üstün performansı, mRNA araştırmaları ve terapötik geliştirme alanında önemli bir sıçramayı göstermektedir.
Rahim içi hiperglisemi, cinsiyete özgü epigenetik yeniden programlama müdahalesi yoluyla fare ilkel germ hücresi gelişimini ve doğurganlığını bozar için yorumlar kapalıBİLİM, sağlık
Hiperglisemi gibi olumsuz intrauterin ortamlar, eşeyli üremeyi ve tür devamlılığını bozar, ancak altta yatan mekanizmalar hala yeterince anlaşılmamıştır. Bu çalışmada, intrauterin hipergliseminin, özellikle dişi yavrularda, primordial germ hücresi (PGC) gelişimini önemli ölçüde bozduğunu ve böylece doğurganlığı azalttığını gösterdik. Rahim içi hiperglisemiye maruz bırakılan Oct4-EGFP transgenik fareleri kullanarak, hipergliseminin PGC gelişimi sırasında cinsel olarak spesifik kromatin erişilebilirliğini ve DNA metilasyon yeniden programlamasını tehlikeye attığını ortaya koyduk
Gen İfade Programlama ve Fizik Bilgili Sinir Ağları Kullanılarak Köprü İskelesi Aşınmasının Yorumlanabilir Veri Odaklı Modellenmesi için yorumlar kapalıBİLİM, GENETİK
Köprü ayaklarındaki aşınma, normalleştirilmiş aşınma derinliğinin tahminini geliştirmek için gelişmiş makine öğrenimi yaklaşımları kullanılarak araştırıldı. Gen ifadesi programlama (GEP), üç çeşit fizik bilgili sinir ağı (PINN) ve bir temel yapay sinir ağı geliştirildi ve 569 laboratuvar ölçeğinde veri içeren USGS ayak aşınma veritabanı kullanılarak değerlendirildi.
Entegre biyoenformatik ve deney doğrulaması, sepsis kaynaklı miyokardiyal disfonksiyonda kuproptozla ilişkili biyobelirteçleri ve terapötik hedefleri ortaya koyuyor için yorumlar kapalıBİLİM, GENETİK
Sepsis kaynaklı miyokard disfonksiyonu (SİMD), yüksek mortaliteye sahip ciddi bir sepsis komplikasyonudur, ancak mevcut tanı ve tedavi yaklaşımları sınırlıdır. Erken dönemde spesifik biyobelirteçlerin ve etkili tedavilerin eksikliği, yeni mekanizmaların araştırılmasını gerektirmektedir. Son zamanlarda kuproptozis çeşitli hastalıklarla ilişkilendirilmiştir, ancak SİMD’deki rolü belirsizdir. Bu çalışma, hayvan modeli doğrulamasıyla desteklenen kuproptozis ile ilişkili biyobelirteçleri ve potansiyel tedavi ajanlarını belirlemeyi amaçlamaktadır.
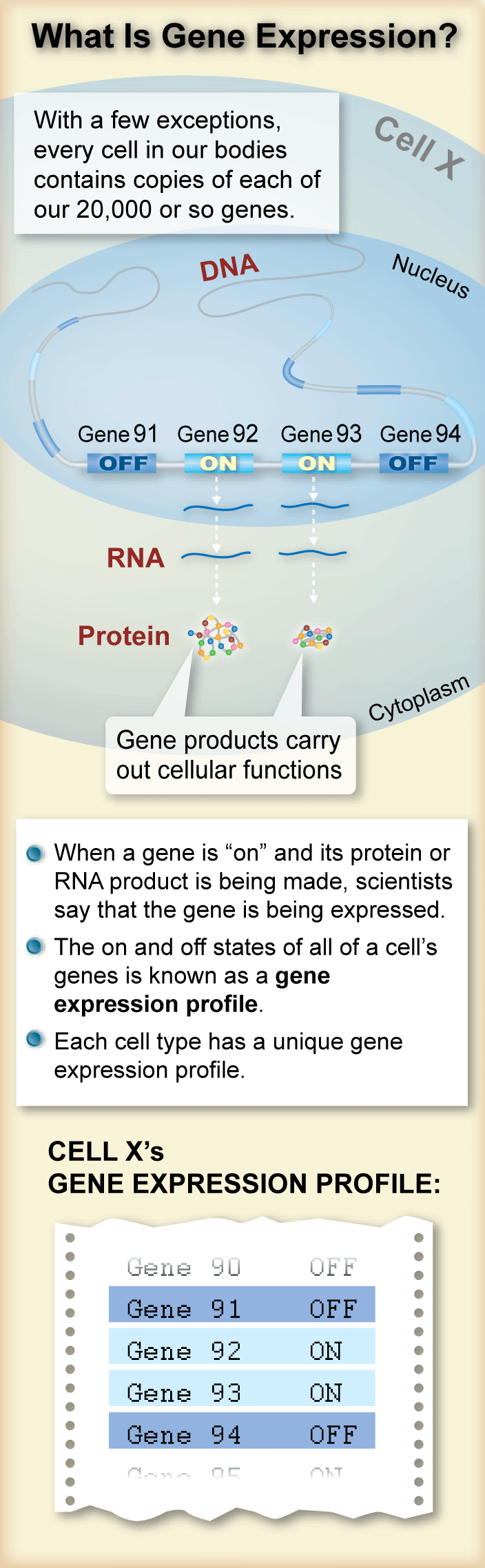
DNA’mızdaki küçük farklılıklar, bireylerin bir ilaca verdiği tepkilerdeki veya bir hastalığa yakalanma risklerindeki farklılıklarla ilişkilendirilebilir. Genellikle bu farklılıklar, bir genin protein kodlama bölümünü oluşturan DNA harflerinde meydana gelir ve proteinin nasıl çalıştığını etkiler.
Protein kodlama dizisini değiştirmek, bir geni etkilemenin tek yolu değildir. Gen ifadesinin seviyesini değiştirmek (böylece ondan yapılan RNA veya protein miktarını artırmak veya azaltmak) biyolojik süreçleri de aynı derecede önemli ölçüde etkileyebilir.
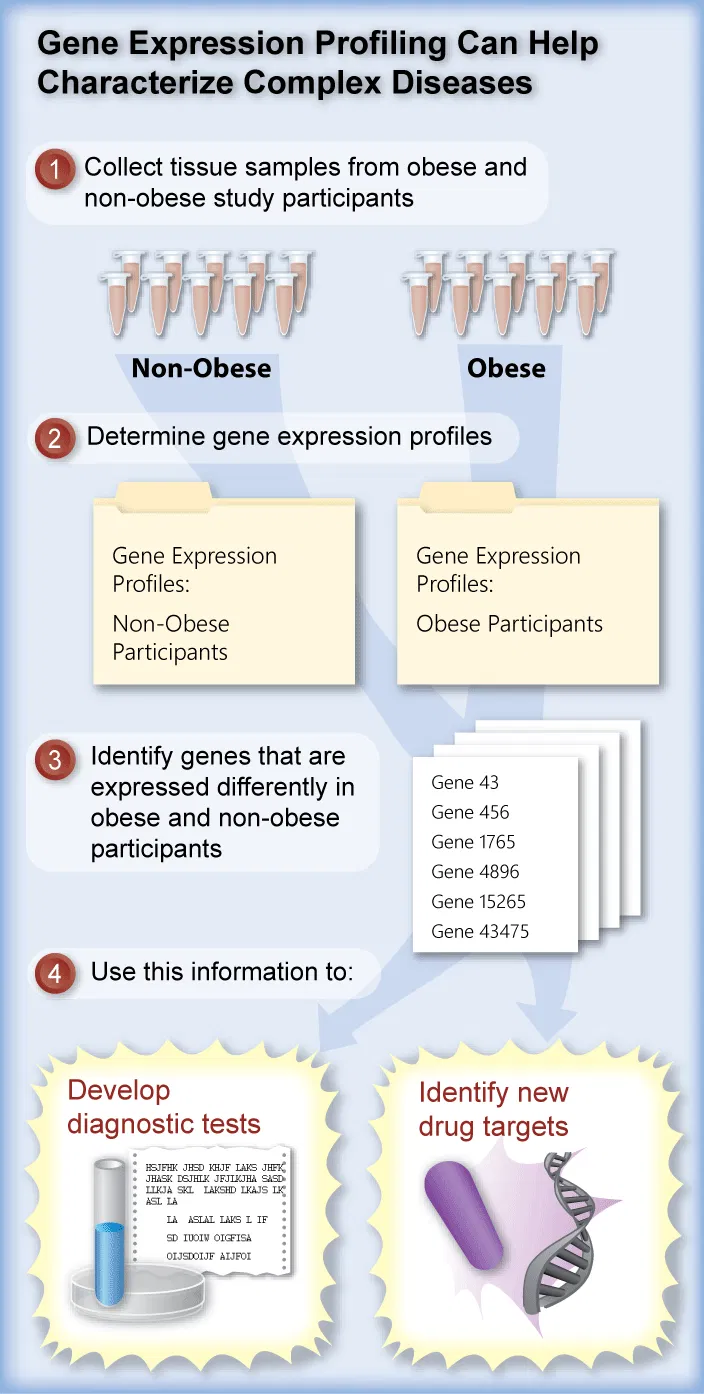
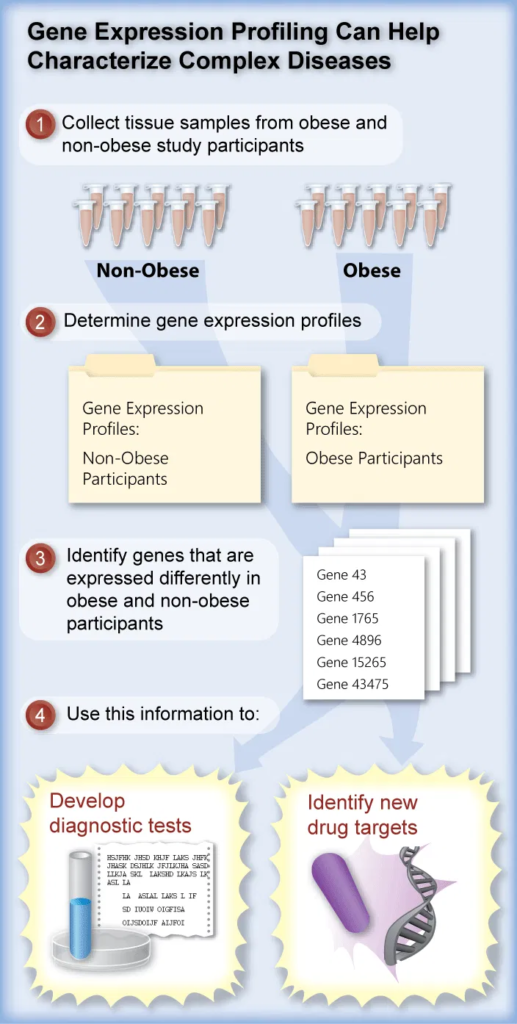
Gen ifadesinin hastalık riskiyle nasıl ilişkili olabileceğinin bir örneği olarak obeziteye bakalım:
Obezite, Amerika’da çocukları ve yetişkinleri tehdit eden büyük bir sağlık riskidir. Özellikle insanlar yaşlandıkça kalp hastalığına, yüksek tansiyona ve diyabet hastalığına yol açabilir. Karmaşık bir tıbbi durum olan obezite, diyet, egzersiz, metabolizma ve genetikten etkilenir.
17 yaşındaki Shan, boyuna göre 40 pounddan fazla kiloludur. Ebeveynleri ve büyükanne ve büyükbabası da kiloludur.
Allen, yaş, boy, beslenme ve egzersiz alışkanlıkları açısından Shan’a benzer, ancak aşırı kilolu değildir. Ayrıca, Allen’ın ailesinde aşırı kilolu kimse yoktur.
Hem Shan’ın hem de Allen’ın aileleri, obezitede rol oynayan genleri belirlemek için bir üniversite çalışmasına gönüllü olarak katılıyor. Araştırmacılar bu soruya nasıl yaklaşacak?
Gen ifadesi düzeylerinin ölçülmesi
Üç nesil aile üyesi araştırmacılara hücre örnekleri (karaciğer ve yağ hücreleri) sağlar. Karaciğer ve yağ hücreleri metabolizmada ve yağ yapımında önemli oldukları için seçilmiştir.
Araştırmacılar, bir hücre veya dokudaki aktif ve inaktif genleri belirlemek için gen ifadesi profillemesi adı verilen bir yaklaşımı kullanacaklar.
İfade profili daha sonra bilim insanına obezitede hangi genlerin rol oynayabileceğini söyler.
Bilim insanları, tüm aile bireylerinin yanı sıra, çalışmaya katılan diğer kişilerin de benzer ifade profili çalışmalarını yürütüyorlar.
Bilim insanları çalışmadaki herkesin sonuçlarını karşılaştırdığında, hangi genlerin obezitede rol oynadığına dair iyi bir fikre sahip olurlar. Bu bilgi gelecekteki çeşitli uygulamalarda kullanılabilir:
1. Hastanın obeziteye genetik yatkınlığı olup olmadığını tahmin etmeye yönelik tanı testleri oluşturmak.
Bir test, obeziteye yatkınlığı öngören genetik imzaları tespit etmek amacıyla kişinin obeziteyle ilişkili genlerinin DNA dizisini inceleyebilir.
Başka bir testte, obeziteye yatkınlığı gösteren anormal gen ifadesi kalıpları için doku örneği incelenebilir.
2. İlaç Tasarımı
Obeziteyi tedavi etmek veya önlemek için tasarlanmış ilaçlar. Bu, tanımlanan obezite genlerinin protein ürünlerini izole ederek, moleküler yapılarını ve işlevlerini belirleyerek ve bunları inhibe eden ilaçlar yaparak yapılabilir.
Obezite genlerinin ifadesini kontrol etmek için ilaçlar tasarlamak. Bu ilaçlar, obezitede aktive olan genlerin açılmasını önlemek için anahtar hücrelerdeki ve dokulardaki DNA ile doğrudan etkileşime girecek veya tam tersine, obezite sırasında inaktif olan genlerin kapatılmasını önleyecek.
Bilim İnsanları Kromozomları Nasıl Okuyor? için yorumlar kapalı
Bilim insanları bir kromozom setini “okumak” için benzerliklerini ve farklılıklarını belirlemek amacıyla üç temel özelliği kullanırlar:
Boyut. Bu kromozomları birbirinden ayırmanın en kolay yoludur.
Bantlama deseni. Giemsa bantlarının boyutu ve konumu her kromozomu benzersiz kılar.
Sentromer pozisyonu. Sentromerler bir daralma olarak görünür. Hücre bölünmesi (mitoz ve mayoz) sırasında kromozomların yavru hücrelere ayrılmasında rol oynarlar.
Bilim insanları bu temel özellikleri kullanarak 46 kromozomun tamamını, yani her ebeveynden 23’er kromozomdan oluşan bir seti belirleyebilirler.
Sentromerler ne işe yarar?
Hücre bölünmesi sırasında kromozom ayrımı için sentromerler gereklidir. Sentromerler, hücre bölünmeden önce çift kromozomları hücrenin zıt uçlarına çeken protein lifleri olan mikrotübüller için bağlanma noktalarıdır. Bu ayrım, her yavru hücrenin tam bir kromozom setine sahip olmasını sağlar.
Her kromozomun yalnızca bir sentromer’i vardır.
Sentromer Pozisyonları
Sentromerin uçlara göre konumu, bilim insanlarının kromozomları birbirinden ayırmasına yardımcı olur. Sentromer konumu üç şekilde tanımlanabilir: metasentrik, submetasentrik veya akrosentrik.
Metasentrik (met-uh-CEN-trick) kromozomlarda sentromer kromozomun merkezine yakın bir yerde bulunur.
Submetasentrik (SUB-met-uh-CEN-trick) kromozomların sentromerleri merkezden uzaktadır, böylece bir kromozom kolu diğerinden daha uzundur. Kısa kol “p” (petite için) olarak adlandırılır ve uzun kol “q” olarak adlandırılır (çünkü “p” harfini takip eder).
Akrosantrik (ACK-ro-CEN-trick) kromozomlarda sentromer bir uca çok yakındır.
Learn.Genetics Nedir? için yorumlar kapalıLearn.Genetics
Learn.Genetics Utah, genetik bilimleri konusunda hem öğrencilere hem de meraklılara yönelik kapsamlı ve ücretsiz bir online eğitim platformudur. Utah Üniversitesi’nin Genetik Bilim Öğrenme Merkezi tarafından oluşturulan bu site, genetik bilimlerinin temel kavramlarından karmaşık konularına kadar geniş bir yelpazede içerik sunar.
Neden Learn.Genetics Utah? Kapsamlı İçerik: DNA, genler, kalıtım, evrim gibi temel genetik konularının yanı sıra genetik hastalıklar, biyoteknoloji, genetik mühendisliği gibi daha spesifik konularda da detaylı bilgiler bulabilirsiniz. Görsel İçerik: Animasyonlar, simülasyonlar ve görseller sayesinde karmaşık genetik kavramlar daha anlaşılır hale getirilir. Eğitici Araçlar: Interaktif etkinlikler, quizler ve oyunlar sayesinde öğrenme süreci daha eğlenceli hale gelir. Güncel Bilgiler: Genetik bilimindeki son gelişmeler düzenli olarak siteye eklenir. Çok Dilli: İngilizce dışında farklı dillerde de kaynaklar bulunmaktadır. Learn.Genetics Utah’ın Kimler İçin Uygun? Öğrenciler: Lise ve üniversite düzeyindeki biyoloji öğrencileri için mükemmel bir kaynak. Öğretmenler: Sınıflarında genetik konularını işleyen öğretmenler için hazır ders materyalleri ve etkinlikler sunar. Meraklılar: Genetik hakkında daha fazla bilgi edinmek isteyen herkes için açık ve anlaşılır bir kaynak. Learn.Genetics Utah’ta Neler Bulabilirsiniz? Konu Anlatımları: Genetikle ilgili temel kavramların detaylı açıklamaları. Animasyonlar ve Simülasyonlar: Karmaşık genetik süreçlerin görsel olarak anlatımı. İnteraktif Etkinlikler: Öğrencilerin aktif olarak katılımını sağlayan etkinlikler. Haberler ve Makaleler: Genetik alanındaki son gelişmeler hakkında güncel bilgiler. Kaynaklar: Kitaplar, makaleler ve diğer eğitim materyallerine bağlantılar. Özetle Learn.Genetics Utah, genetik bilimlerini öğrenmek ve öğretmek için harika bir platformdur. Kapsamlı içeriği, görsel öğeleri ve interaktif özellikleri sayesinde genetik bilimleri daha erişilebilir hale getirir.
W3School WEB Sitesi nedir? ne amaçla kullanılır? için yorumlar kapalıW3school
W3Schools, web geliştirme öğrenmek isteyenler için oldukça popüler ve ücretsiz bir online eğitim platformudur. HTML, CSS, JavaScript gibi temel web teknolojilerinden daha gelişmiş konulara kadar geniş bir yelpazede dersler sunar.
Neden W3Schools? Ücretsiz Erişim: Tüm içeriklere ücretsiz olarak ulaşabilirsiniz. Pratik Öğrenme: Teorik bilgilerin yanı sıra canlı örneklerle ve “try it yourself” editörleriyle öğrendiklerinizi hemen deneyebilirsiniz. Geniş İçerik: HTML, CSS, JavaScript’in yanı sıra SQL, Python, PHP gibi birçok programlama dilini ve diğer web teknolojilerini de öğrenebilirsiniz. Basit Arayüz: Site, yeni başlayanlar için bile oldukça kullanıcı dostudur. Topluluk: Sorularınızı sorabileceğiniz ve diğer öğrencilerle etkileşimde bulunabileceğiniz bir topluluk bulunmaktadır. W3Schools’un Avantajları ve Dezavantajları Avantajları:
Hızlı Başlangıç: Temel bilgileri hızlıca öğrenmek için idealdir. Güncel İçerik: Web teknolojilerindeki gelişmeler takip edilerek içerikler düzenli olarak güncellenir. Çok Dilli: Farklı dillerde eğitim imkanı sunar. Dezavantajları:
Derinlemesine Olmaması: Bazı konular yeterince derinlemesine işlenmeyebilir. Daha kapsamlı bilgi için diğer kaynaklara başvurmanız gerekebilir. Doğruluk Tartışmaları: Bazı kullanıcılar, W3Schools’daki bazı bilgilerin tam olarak doğru olmadığını veya en iyi uygulamaları yansıtmadığını iddia eder. Bu nedenle, öğrendiğiniz bilgileri farklı kaynaklardan da doğrulamanız faydalı olacaktır. W3Schools’u Kimler Kullanabilir? Yeni Başlayanlar: Web geliştirmeye yeni başlayanlar için mükemmel bir başlangıç noktasıdır. Öğrenciler: Okulda veya üniversitede web geliştirme dersleri alan öğrenciler için ek bir kaynak olabilir. Profesyoneller: Bilgilerini tazelemek veya yeni teknolojileri öğrenmek isteyen profesyoneller de W3Schools’u kullanabilir. Özetle W3Schools, web geliştirme dünyasına adım atmak veya mevcut bilgilerinizi geliştirmek için kullanışlı bir platformdur. Ancak, tek başına yeterli olmayabilir. Diğer kaynaklarla destekleyerek daha sağlam bir temel oluşturabilirsiniz.
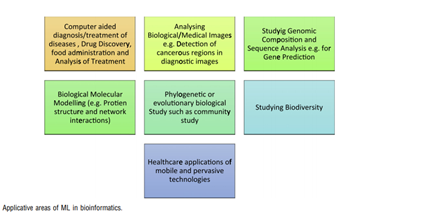
Biyoinformatikte Makine Öğrenmesi Ve Teknikleri için yorumlar kapalı
“Amerikan Ulusal Biyoteknoloji Bilgi Merkezi NCBI’nın (National Center for Biotechnology Information) internet sayfasında biyoinformatik; biyoloji, bilgisayar bilimi ve bilgi teknolojilerinin birleşiminden oluşan bir disiplin olarak tanımlanmıştır”, “Biyoinformatik multidisipliner çalışmaktadır. Bilgisayar bilimleri, biyoistatistik sayesinde biyokimya ve biyoloji, genetik, tıbbi biyoloji hatta fizyoloji gibi biyomedikal bilimlerinin bir bütününün sonucu olarak karşımıza çıkmaktadır. Bir diğer benzer tanımlamayı Luscombe ve arkadaşları da kullanmıştır. Şimdi kavram olarak bir fikre sahip olduğunuza göre biyoinformatik teriminin tarihçesine kısaca değinmek isterim.
Pauling ve Corey’in 1951 yılında proteinlerin sekonder yapılarının doğru bir şekilde tahmin edilmesi ile ilgili geliştirdikleri yaklaşım biyoinformatik için başlangıç kabul edilmekle birlikte asıl olarak başlangıç 1966 yılında bilgisayarla moleküler grafiklerin çizimine ait ilk makalenin “Scientific American” isimli dergide yayınlanmasıyla olmuştur. Ayrıca biyoinformatik alanında önemli bir yere sahip olan İnsan Genom Projesi ise 1990’da başlamıştır. Projenin amaçları ise DNA ve protein bilgilerinin yer aldığı veri tabanları, insan DNA’sındaki 20.000-25.000 genin tanımlanması, hastalıkların erkenden tedavi edilmesinin sağlanması şeklinde sıralayabiliriz.
Biyoinformatiğin Temel Hedefleri
Biyoinformatik biliminin üç ana hadefi vardır.İlk hedefi ilgili kişilerin biyolojik verilere ulaşabilmesini ve yenilerinin de yüklenebileceği bir şekilde düzenlenmesidir. Buna veri tabanı oluşturmak diyoruz. Analiz edilmeyen veri tabanındaki bilgiler kullanışsız bilgi olarak kabul edilmektedir.Analiz kısımlarında kullanılan teknikler ve araçları geliştirmek de biyoinformatiğin ikinci hedefi olarak karşımıza çıkar. Bu konuyu basite alamayız. Örnek verecek olursak aminoasit dizisinin belirli bir proteiniyle dizi özellikleri belirli olan bir diğer proteinin karşılaştırma durumunda yazılım araştırması yeterli gelmeyecek olup bu moleküllerin biyolojik içeriklerinin de incelenmesi gerekebilir. Bunun için kullanılan BLAST nükleotid/protein dizisi karşılaştırması yapan bir algoritma olup bunun gibi yazılım kaynaklarının geliştirilmesi hususunda da biyoloji bilgisi gerektiği kadar bilişim alanlarında da uzmanlık şarttır. Üçüncü hedef ise elde edilen bilgileri biyolojik açıdan anlamlı bir şekilde analiz etmektir.
Günümüze Gelecek Olursak…
Son zamanlarda hepimizin sıklıkla duyduğu kavramlar arasında büyük veri (big data) yer almaktadır. İnternet kullanan her bireyin büyümesine ve gelişmesine katkı sağladığı büyük veri; gözlemlerden, araştırmalardan, arama motorlarından, bloglardan, forumlardan, sosyal medyadan ve diğer birçok kaynaktan elde edilen verilerin anlamlı ve işlenebilir hale getirilmiş biçimine denir.
Farklı bilim dallarının yer aldığı biyoinformatikte ise genom dizileme, omiks çalışmalar, mikrodizi gen ifade, ilaç molekül çalışmaları ile ilişkisinin bulunması,biyolojik verilerin artması sorunlarını da beraberinde getirmektedir. Biyoinformatikte en büyük problemlerden olan ikinci problem bahsedilen tüm bu verilerin biyolojik bilgilere dönüştürülme hususunda kullanılan yöntem ve araçların iyi bilinmesi gerekir. Bu yöntem araçlarının uygulanmasında bilgisayar bilimleri ve biyoistatistik gibi disiplinlerin entegrasyonundan ortaya çıkan teknikler uygulanmaktadır. Size birkaç biyoinformatik uygulamasından bahsedeceğim. Bu uygulamalar yalnızca var olan uygulamaların çok az bir kısmını oluşturduğunu da bilmenizi isterim.
Homologlar
Biyoinformatik farklı biyomoleküller arasındaki benzerlikleri aramaktadır. Bu konuda sistematik olarak veri organizasyonu sağlamadan protein türdeşlerini tanımlamada kullanılan pratik uygulamalar mevcuttur. Bunlardan biri proteinler arası gerçekleşen bilgi aktarımıdır. Örnek verecek olursak elimizde karakteristiği tam olarak belirlenmemiş protein için daha iyi anlaşılabilmesi adına homologları bulunarak elde edilen bilgiler değerlendirilir ve veri yetersiz kaldığında, bu yapılan çalışmalar düşük seviyeli organizmalardan insan gibi üst düzey organizmalardaki homologlarda bile uygulanır.
Rasyonel İlaçların Geliştirilmesi
Bir diğer uygulama örneği olan rasyonel ilaçların geliştirilmesi biyoinformatiğin tıbbi çalışmalarıyla mümkün olmuştur. Translasyon yazılımı kullanarak nükleotid sekansı verilen proteinin muhtemel amino asit sekansı belirlenebilmektedir. Burada kullanılan sekans arama teknikleri organizmada homologları bulmada da tercih edilebilmektedir. Bu deneysel çalışmalar başka organizmalarda insana ait protein yapılarını modellemeye olanak tanır. Öte yandan bağlantı algoritmaları sayesinde gerçekte protein üzerindeki etkinliği ölçülerek biyokimyasal tahlillere olanak tanıyabilir ve bu şekilde de protein yapısına bağlanan moleküller tasarlanmaktadır. Bahsedilen Gen ekspresyon analizleri hastalık teşhisi ve hedef ilaç tasarımında yararlanılmaktadır.
Veri Tabanları
Biyoinformatiğin en önemli işlevlerinden birisi de veri kaynaklarından elde edilen bilgilerin birleştirilmesidir.Bu durum avantajlı olmasına rağmen dizinlerdeki ve dosya biçimlerindeki farklılıklar sebebiyle bilgi kaynaklarını etkili kullanırken sıkıntı yaratabilmektedir. Temel düzeyde, bu sorunun çözümüne yönelik olarak birçok veri kaynağına erişim sağlanabilecek şekilde veri kaynaklarını birleştirme çabası vardır. Bu konu için 2 erişim sistemi mevcuttur. Biri düz dosya veri tabanlarının birbirlerine endekslenmesine, protein yapısına, dizisine olanak sağlayan, Dizi Erişim Sistemidir (Sliding Rail System). Diğeri de DNA’ya, protein dizilerine, genom harita verilerine, 3D makromoleküler yapılara ve PubMed bibliyografik veri tabanına benzer yollarla erişim sağlayan Entrez sistemidir. Yukarıda da bahsettiğim gibi biyoinformatik adı altında yapılan uygulamalar çok önemli hizmetler vermektedir. Ayrıca bahsettiklerimden daha fazla çalışma alanları mevcuttur.
Büyük Veri Doğru Kullanılırsa
Büyük verinin dezavantajları olduğu gibi avantajları da mevcuttur. Bahsedilen kanser ve nirodejeneratif hastalıklar gibi ciddi hastalıkların erken uyarı sistemleri, ilaçların keşfi, salgınların tahmini konularında bilginin artmasını sağlar. Böylece bu bilgilerimizi artıracak yeni teşhis araçlarının ortaya çıkmasına öncülük etmektedir.
Artık biyoinformatik üzerine yüzeysel ama geniş çaplı bir fikriniz olduğuna göre biyoinformatiğin makine öğrenmesiyle yollarının hangi noktalarda kesiştiğine değinmek isterim.
Makine Öğrenmesi ve MÖ Algoritmaları
Hesaplama konusundaki zorluğun artması ve büyük verinin hacimsel potansiyeli sonucunda derin öğrenme son teknolojiyle birlikte başarılı makine öğrenme (machine learning) algoritmaları haline gelmiştir. Makine öğrenim teknikleri, biyolojik verilerden bilgiyi çıkarma konusunda hesaplama yöntemleri olarak yardımcı olmaktadır. Aynı zamanda bu teknikler model oluşturmaya da yardımcı olduğu için biyoinformatik alanında oldukça önemlidir. ML modeller biyoinformatikte biyolojik verileri öğrenir ve bunlara ilişkin tahminlerde bulunur.Kafanızda daha çok canlanması adına “Machine Learning in Bioinformatics,Jyotsna T Wassan, Haiying Wang, and Huiru Zheng, Ulster University, County Antrim, Northern Ireland, United Kingdom,2018” adlı makelede geçen örnekten bahsetmek isterim.
F(x)=y olarak bildiğimiz fonksiyon gösteriminden yola çıkarsak
Eğer X biyolojik veri olarak hareket ederse, Y, X’ten türetilmiş biyolojik bilgidir.
Diğer bir durumda X biyolojik veri olarak hareket ettiği takdirde, F, X’e göre fonksiyonel yaklaşım olmaktadır. Y ise yeni türetilmiş biyolojik bilgidir.
Artık size biyolojik tahminler için temsili makine öğrenimi algoritmalarından bahsedebilirim.
Sınıflandırma
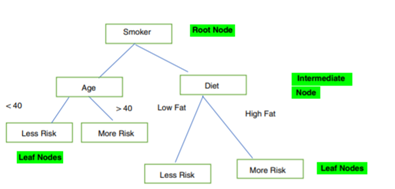
Sınıflandırma problemini baz aldığımızda veri ögeleri kümesinin sınıflar olarak bölünmesi gerekir. Bir öge kümesi ögelerin bazı özelliklerine göre bir dizi sınıflandırma kuralına göre bir sınıf atanmaktadır. Bunlardan en bilinen karar ağaçları biyolojik verilerdeki özellikler arası ilişkinin hiyerarşik temsilidir. Bir dizi özelliğin sınıflandırılmasına dayanan yöntemde aşağıdaki şekli de baz alırsak yaprak, düğümler kategori/sınıflara göre sınıflandırılan örnekleri temsil eder.
Bir diğer sınıflandırma da Rastgele Orman ve XGBoost olarak adlandırılır. Rastgele bir gözlem örneği alınır ve bir karar ağacı modeli oluşturmak için ilk ögeler seçilir. Süreç birçok kez tekrarlanır. Son olarak da farklı karar ağaçlarından türetilen her bir öngörünün fonksiyonun tahmin gerçekleştirilir. Rastgele Ormanı daha hızlı yapmak için XGBoost hesaplamadan yararlanılır. XGBoost, karar ağacı tabanlı bir topluluk Makine Öğrenimi algoritmasıdır. En az bilgi işlem miktarıyla daha büyük verilere ölçeklenmesine olanak tanır.
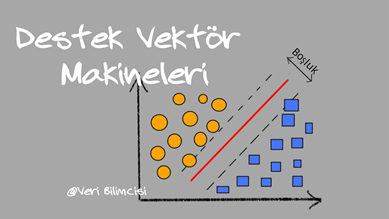
Destek Vektör Makineleri
Bu sistemde amaç şekilde de görüldüğü üzere verileri ayıran bir çizgi sunmaktır. Hat bir sınıflandırma görevi görmektedir. Örneğin iki örnek özelliği varsa (yaş ve sigara içme durumu olarak düşünebiliriz) bir birey olarak iki değişken, iki boyutlu bir boşlukta çizilir. Her noktanın dolayısıyla iki koordinatı vardır.
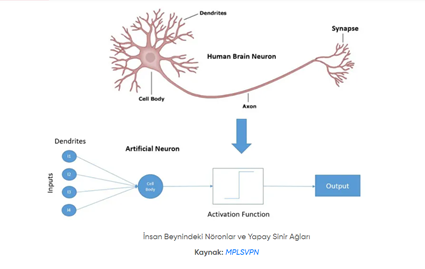
Yapay Sinir Ağları
Makine öğrenmesi Yapay Sinir Ağları kavramını da beraberinde getirmiştir. Bu kavram insan beynin özelliği olan öğrenme mekanizmasının basit düzeyde adeta simüle edilmiş hali olarak karşımıza çıkmaktadır. Yapay sinir ağları, insan beyni gibi girdiler, işlemler, çıktılardan oluşmaktadır. İnsan beyninde nöronlardaki dentritler diğer nöronlardan bilgiyi alır. Daha sonrasında bilginin işlenmesinde aracı olur. Bilgiler hücre gövdesinde işlenir ve aksonlar da bu bilgileri sinapslara iletir. Sinapslar da diğer nöronlar ile haberleşmek için adeta bir çıktı görevi görmektedir .Yapay sinir ağlarında ise temel işlem birimleri(nöronlar veya düğümler) katmanlar halinde ve genellikle iki ardışık kavramın bağlanması şeklinde organize edilmektedir. Nöral ağ yapısında bir ünite önceki katmana ait birkaç ünite hakkında bilgi alır. Algıron adı verilen en basit nöral ağ ,eşik etkinleştirme işlevi kullanarak 2 sınıfı doğrusal bir şekilde ayıran tek nöron sınıflandırıcıdır. İleri bir yapı olarak da algıları birbirine bağlayan bir nöron tasarımı oluşturulabilir. Buna da çok katmanlı algıron adı verilmektedir.
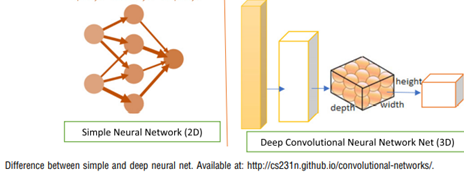
Kümeleme
Kümeleme makine öğrenmesi algoritmalarından bir diğeri olarak karşımıza çıkmaktadır. Kümele içsel gruplandırmaya dayanmaktadır. Grup üyelerini birbirine benziyor ve diğer gruplara ait öğelere benzemiyorlar olarak düzenleyen bir tekniktir. Kümeleme yöntemleri de kendi içerisinde Bölünme yöntemleri, Hiyerarşik yöntemler, Association Rule Madenciliği, Derin Evrişimli Ağlar olarak ayrılmaktadır. Aşağıdaki şekilde de görüldüğü üzere derin evrişimli ağlar 2 boyutlu nöral ağların aksine genişlik yükseklik ve derinlik olarak çıkmaktadır.
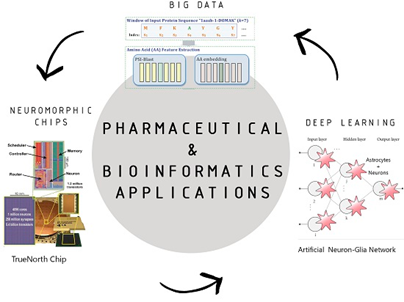
Bu ağların tanımını açmamdaki en büyük neden de ilaç keşfinde bu ağların başarıyla kullanılmasıdır. Moleküler ve biyolojik proteinler arasındaki etkileşimin tahmin edilmesinden potansiyel tedaviler elde edilmektedir. Makine öğrenimi için kullanılan algoritmalar hakkında fikir sahibi olduğunuza göre kullanılan araçlar nelerdir sorusuna yanıt vermek için aşağıda incelediğim birkaç araçtan bahsetmek isterim. Bahsedeceğim araçlar veri hazırlığı ve öngörülü modellemeye yardımcı olmaktadır.
MLYazılımları
ML yazılımları biyolojik etki alanındaki sorunları çözen veri biliminin ayrılmaz bir parçası haline gelmiştir. Bu dört araçtan ilki RapidMiner ilk olarak 2001 yılında Ralf Klinkenberg tarafından java programlama dilinde geliştirilmiştir. Şablon tabanlı bir blok diagram yaklaşımına dayanan açık kaynaklı bir Grafik Kullanıcı Arabirimi görevi görür.Ayrıca 2016 yılında yürütülen yıllık yazılım anketi ile en popüler veri analizi yazılımı olduğu ilan edilmiştir. KDnuggets (Jupp 2011). Biyoinformatik iş akışlarına ML araçlarının toplu bir şekilde uygulanmasını sağlamıştır.
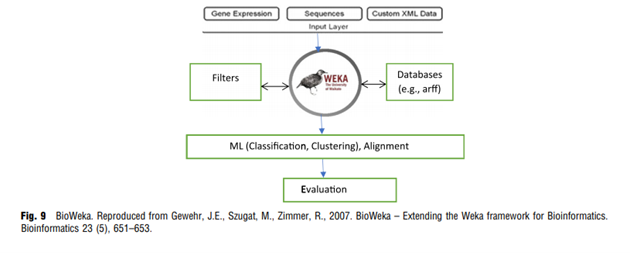
İkinci yazılım örneği ise Bioweka‘dır. Bilgi analizi için Weka ortamı, iyi görselleştirmeye sahip unsur seçimi gibi veri ön işleme yöntemleriyle çeşitli sınıflandırma, regresyon, kümeleme algoritmalarını destekler. Şekilde de gösterildiği gibi BioWeka projesinin bir parçası olarak Weka ‘ya biyoinformatik yöntemlerini tanıtmıştır.
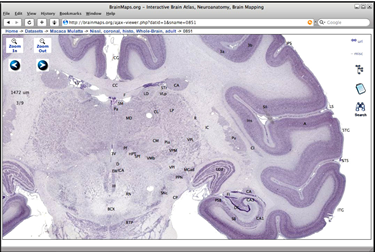
Bir diğer örnek vereceğim araç, Biyomedikal Mühendisi olarak da kullandığım MATLAB biyolojik sistemlerin modellenmesi ve simülasyonu konusunda entegre bir ortam sağlar. Mikrodiziler üzerinden veri analizi gerçekleştirmek için MATLAB ve ilgili araç kutuları kullanılmaktadır. Biyomkimyasal bileşikleri ölçmek, tıbbi görüntü işleme, biyolojik ve biyoistatistiksel simülasyon yapmak için çok fazla tercih edilen bir araçtır. Simbioloji kütüphanesi sayesinde sistemler için bir grafik ve modelleme aracı sağlamaktadır. MATLAB’ ın biyolojik görselleştirmede yararlı olduğu kanıtlanmıştır. Örneğin, BrainMaps şekilde de görüldüğü üzere yüksek çözünürlüklü beyin görüntü verilerini analiz etmekte kullanılır. MATLAB’a alternatif olarak da R, Python gibi açık kaynaklı programlama dilleri kullanılmaktadır.
Son olarak bahsedeceğim R-Project biyolojik verilerde en güçlü istatistiksel araç olarak ortaya çıkmasıyla birlikte analiz ve görselleştirme için çeşitli paketler sunmaktadır. Yaygın olarak üretilen moleküler genomik veriler ile bunların işlenmesi için ihtiyaç duyulan açık kaynak kodlu bir araçtır. R programlama dili kısaca veri analizi, verileri temizlemek, görselleştirmek, analiz etmek, istatistiksel hesaplama alanlarında kullanılan bir programlama dilidir.
Özetle ML tekniklerinin uygulanması gen montajı, veri analizi, moleküler yapısal modelleme dahil olmak üzere birçok biyolojik patternleri ve tahminleri bulmaya odaklamaya yardımcı olmaktadır. Şimdi ve gelecekte de biyolojik veriler katlanarak büyüdükçe, gelecek biyoinformatik için ölçeklenebilir Ml algoritmalarını geliştirmekte yatmaktadır. Aşağıda da belirttiğim, yazımda da kullandığım ve ek olarak eklediğim kaynaklara bakmanızı tavsiye ederim. Bu alanda yapılan çalışmaları en azından araştırmaya başlamak bile bir adım olduğu için sizlere bu yazımı ulaştırmak istedim.
Dilara Akbunar’ın anlatımıyla Biyoinformatikte Makine Öğrenmesi ve Tekniklerinin devamına buradan ulaşabilirsin.