

Araştırmacılar, yaklaşık yarım milyar insanı etkileyen 50’den fazla insan hastalığıyla ilişkilendirilen bir süreç olan proteinlerin yapışkan kümeler oluşturup oluşturmadığını ve neden oluşturduğunu tahmin edebilen bir yapay zeka sistemi geliştirdiler.
Yeni bir yapay zeka aracı, proteinlerin Alzheimer hastalığı ve yaklaşık elli diğer insan rahatsızlığıyla ilişkili yapılar olan yapışkan kümeler oluşturup oluşturmadığını belirleyen biyokimyasal “dil”in kodunu çözmede önemli ilerleme kaydetti . Geleneksel “kara kutu” yapay zeka sistemlerinin aksine, CANYA adlı bu araç, özellikle tahminlerini açıklamak için tasarlandı. Zararlı protein kümelenmesini teşvik eden veya engelleyen kesin kimyasal kalıpları vurgular.
Science Advances dergisinde ayrıntıları verilen bu çığır açıcı gelişme , protein agregasyonu üzerine şimdiye kadar bir araya getirilen en büyük veri kümesi sayesinde mümkün oldu. Çalışma, dünya çapında 500 milyondan fazla insanı etkileyen hastalıklarda rol oynayan bir süreç olan protein kümelenmesinin ardındaki moleküler mekanizmalara ışık tutuyor.
Protein agregasyonu, amiloid oluşumu olarak da bilinir, normal hücresel işlevlere müdahale eder. Bir proteinin belirli bölgeleri yapışkan hale geldiğinde, moleküllerin hücreler için genellikle toksik olan yoğun, lifli yapılara bağlanmasına neden olduğunda meydana gelir.
Tıp ve Biyoteknoloji İçin Sonuçlar
Çalışmanın nörodejeneratif hastalıklar için araştırma çabalarını hızlandırmak için bazı çıkarımları olsa da, daha acil etkisi biyoteknolojide olacak. Birçok ilaç proteindir ve genellikle istenmeyen kümelenmeler tarafından engellenirler.
Çalışmanın eş yazarı ve Katalonya Biyomühendislik Enstitüsü’nde (IBEC) Grup Lideri olan Dr. Benedetta Bolognesi, “Protein agregasyonu ilaç şirketleri için büyük bir baş ağrısıdır” diyor.
“Eğer bir terapötik protein toplanmaya başlarsa, üretim partileri başarısız olabilir, bu da zaman ve para kaybına yol açabilir. CANYA, birbirine yapışma olasılığı daha düşük antikorlar ve enzimler üretme çabalarına rehberlik edebilir ve süreçteki masraflı aksaklıkları azaltabilir” diye ekliyor.
Protein Dilinin Kodunu Çözmek
Protein kümeleri, iyi anlaşılmayan bir dil kullanılarak oluşturulur. Proteinler yirmi farklı amino asit türünden oluşur . DNA dilini oluşturan normal A, C, G, T harfleri yerine , bir proteinin dili yirmi farklı harfe sahiptir ve bunların farklı kombinasyonları “kelimeler” veya “motifler” oluşturur.
Araştırmacılar uzun zamandır hangi motif kombinasyonlarının kümeleşmeye neden olduğunu ve hangilerinin proteinlerin hatasız katlanmasını sağladığını çözmeye çalışıyor. Amino asitleri gizemli bir dilin alfabesi gibi ele alan yapay zeka araçları, sorumlu olan kesin kelimeleri veya motifleri belirlemeye yardımcı olabilir, ancak modelleri beslemek için gereken protein kümelenmesiyle ilgili verilerin kalitesi ve hacmi tarihsel olarak yetersizdi veya çok küçük protein parçalarıyla sınırlıydı.
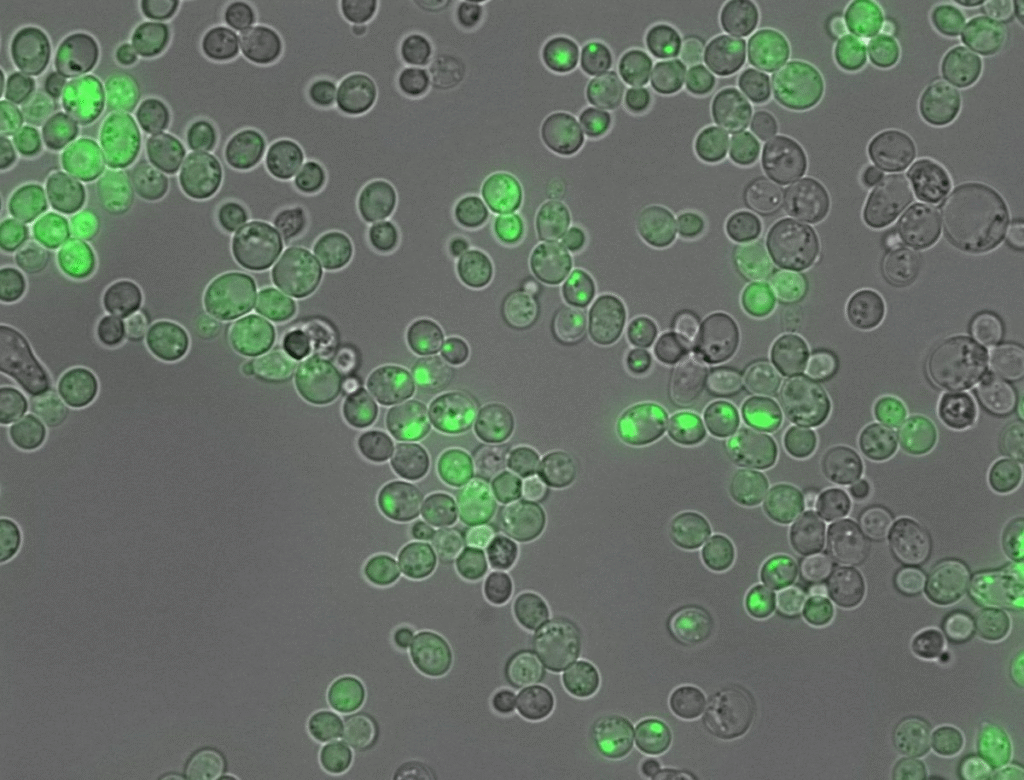
Çalışma, bu zorluğun üstesinden büyük ölçekli deneyler gerçekleştirerek geldi. Çalışmanın yazarları, her biri 20 amino asit uzunluğunda, 100.000’den fazla tamamen rastgele protein parçası oluşturdu. Her sentetik parçanın kümelenme yeteneği, canlı maya hücrelerinde test edildi. Belirli bir parça küme oluşumunu tetiklerse, maya hücreleri araştırmacılar tarafından neden ve sonucu belirlemek için ölçülebilecek belirli bir şekilde büyüyecekti.
Kaynak ve devamına Buradan ulaşabilirsin.