Lu Li 1, Huub Hoefsloot 2, Albert A de Graaf 3, Evrim Acar 4, Yaş K Smilde 5 2
PMID: 35012453
PMCID: PMC8750750
DOI: 10.1186/s12859-021-04550-5
Soyut
Arka plan
Dinamik metabolomik verilerin analizi, metabolizmadaki altta yatan mekanizmaları anlamamızı geliştirme vaadinde bulunur. Örneğin, bir hastalığın başlangıcından dolayı metabolizmadaki değişiklikleri tespit edebilir. Dinamik veya zamanla çözülmüş metabolomik veriler, bir özne moduna, bir metabolit moduna ve bir zaman moduna göre düzenlenmiş girişlerle üç yönlü bir dizi olarak düzenlenebilir. Bu tür zamanla gelişen çok yönlü veri kümeleri giderek daha fazla toplanırken, bu tür verilerden altta yatan mekanizmaları ve dinamiklerini ortaya çıkarmak zorlu olmaya devam etmektedir. Bu tür veriler için, karmaşıklıklardan biri, çeşitli varyasyon kaynaklarının bir araya gelmesinin varlığıdır: indüklenen varyasyon (deneysel koşullar veya doğuştan gelen hatalar nedeniyle), bireysel varyasyon ve ölçüm hatası. Çok yönlü veri analizi (tensör faktörizasyonları olarak da bilinir), çok yönlü verilerdeki altta yatan kalıpları bulmak için veri madenciliğinde başarıyla kullanılmıştır. Çok yönlü veri analizi yöntemlerinin dinamik metabolomik verilerdeki altta yatan mekanizmaları ortaya çıkarma açısından performansını keşfetmek için, bilinen temel gerçekliğe sahip simüle edilmiş veriler incelenebilir.
Sonuçlar
Artan karmaşıklığa sahip farklı dinamik modellerden, yani basit bir doğrusal sistem, bir maya glikoliz modeli ve bir insan kolesterol modelinden kaynaklanan simüle edilmiş verilere odaklanıyoruz. İndüklenen varyasyonun yanı sıra bireysel varyasyona sahip veriler üretiyoruz. Bu tür dinamik metabolomik verileri analiz etmede çok yönlü veri analizinin avantajlarını ve sınırlamalarını ve farklı varyasyon kaynaklarını çözme kapasitelerini göstermek için sistematik deneyler gerçekleştirilir. Çok yönlü veri analizi yöntemlerinin temel gerçeği bilmenin kolaylaştırdığı yeteneğini anlamak istediğimiz için simülasyonları kullanmayı tercih ediyoruz.
Çözüm
Sayısal deneylerimiz, incelenen dinamik metabolik modellerin giderek karmaşıklaşmasına rağmen, tensör faktörizasyon yöntemleri CANDECOMP/PARAFAC(CP) ve Doğrusal Bağımlılıklara Sahip Paralel Profiller (Paralind)’in varyasyon kaynaklarını çözebileceğini ve böylece altta yatan mekanizmaları ve bunların dinamiklerini ortaya çıkarabileceğini göstermektedir.
Arka plan
Nükleer Manyetik Rezonans (NMR) Spektroskopisi ve Kütle Spektrometrisi (MS) ile gaz kromatografisi (GC) veya sıvı kromatografisi (LC) gibi gelişmiş analitik ölçüm tekniklerinin kullanılabilirliğiyle, biyolojik sistemlerden dinamik veya zamana bağlı (veya uzunlamasına) metabolomik verileri toplamak giderek daha popüler hale geliyor. Bu, bu tür verilerin altta yatan biyolojik süreçleri ve mekanizmaları ortaya çıkarabilme vaadini taşıması nedeniyle daha da popüler hale geliyor. Örnekler, bireylerin sağlık durumlarını araştırmak için meydan okuma testlerinin kullanıldığı metabolizma ve sağlık alanından [ 1 ]; belirli gıda bileşiklerinin metabolik kaderinin incelendiği gıda biliminden [ 2 ]; hastalıkların biyobelirteçlerinin ve hastalık durumlarına erken geçişlerin yakalandığı hastalıkların çalışmasından [ 3 ] vb. verilebilir.
Bahsedilen dinamik metabolomik çalışmalarının temel özellikleri, sınırlı sayıda denekten ölçümlerin alındığı sınırlı sayıda zaman noktası ve farklı varyasyon kaynaklarının üst üste gelmesidir. Farklı varyasyon kaynakları açısından, öncelikle, farklı tedavilerden kaynaklanabilen, örneğin [4]’te ele alınan Qingkailing enjeksiyon grubu veya bir enzimin normalden çok daha düşük aktiviteye sahip olduğu bir hastalıktan kaynaklanabilen, örneğin [ 5 ]’te açıklanan insan mutantları, indüklenmiş varyasyon vardır. İkinci olarak, genellikle oldukça büyük olan bireysel (biyolojik olarak da adlandırılır) varyasyon vardır [ 6 ]. Son olarak, cihaza bağlı olan ve önemli olabilen (kaçınılmaz) ölçüm hatası (teknik hata olarak da adlandırılır) vardır [ 7 ]. Tüm bunlar, bu tür dinamik metabolomik verilerin analizini zorlaştırır.
Bu zorluklar göz önüne alındığında, boyut azaltma yöntemleri, gürültü azaltma (örneğin, ölçüm hatasıyla başa çıkma) ve varyasyonun temel temel kaynaklarını yakalama (dinamik metabolomik verileri analiz etmek için farklı yöntemler hakkında bir inceleme için Smilde ve ark. [ 8 ]’e bakın) için ideal olduklarından umut verici yaklaşımlardır. Boyut azaltma teknikleri, verilerde temelde düşük bir boyutluluk olduğu gerçeğini kullanır ve sözde iki yönlü veriler için bu tür yöntemlerin prototipik örnekleri, örneğin Ana Bileşen Analizi (PCA) ve Ortogonal Kısmi En Küçük Kareler (OPLS), gücünü göstermiştir [ 9 ] ve uzunlamasına metabolomik veri analizi için dinamik olasılıklı PCA’ya uzantılar yapılmıştır [ 10 ]. Veriler özneler , metabolitler ve zaman gibi iki moddan fazla moda sahip olduğunda , verileri iki yönlü bir dizi olarak ele almak yerine çok yönlü bir dizi (daha yüksek dereceli tensör olarak da adlandırılır) oluşturulabilir ve çok yönlü diziler için tensör faktörizasyonları [ 11 , 12 , 13 , 14 ] olarak bilinen boyut azaltma yöntemleri bu tür zamansal verileri analiz etmek için kullanılabilir. Daha önce zamanla değişen metabolomik verileri analiz etmek için kullanılan iki yönlü PCA tabanlı yöntemlerle karşılaştırıldığında, tensör faktörizasyonları tüm modlardaki temel desenleri aynı anda sağlama vaadinde bulunur, örneğin özneler , metabolitler ve zaman modlarındaki desenler. Tensör faktörizasyonları, tartışma izleme [ 15 ], zamansal bağlantı tahmini [ 16 ], veri akışlarının analizi [ 17 ], nörogörüntüleme veri analizi [ 18 , 19 , 20 ] ve elektronik sağlık kayıtlarının analizi [ 21 ] için veri madenciliğinde zamanla değişen verileri analiz etmede başarıyla kullanılmıştır . Ancak, dinamik metabolomik analizde tensör yöntemlerinin kullanımı, yakın zamana kadar bu tür uzunlamasına metabolomik verilerin eksikliği ve yöntemlerin metabolomikteki performansının sınırlı anlaşılması nedeniyle şimdiye kadar sınırlıydı. Bir istisna, sıçanlarda toksikolojik bir hasar üzerinde zaman içindeki tedavilerin etkisini incelemek için ASCA (ANOVA-eşzamanlı bileşen analizi) ile birleştirilmiş CANDECOMP/PARAFAC (CP) [ 22 , 23 ] tensör modelinin kullanılmasıdır [ 24 ].
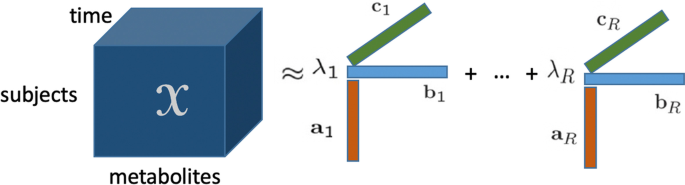
Bu makalede, dinamik metabolomik verileri analiz etmede ve altta yatan mekanizmaları ve dinamiklerini ortaya çıkarmada tensör faktörizasyonlarının potansiyelini araştırıyoruz. Bu tür yöntemlerin temel gerçeğini elde etmek ve sınırlamalarını ve avantajlarını incelemek için, yapılandırılmış doğrusal açık bir sistem, maya glikoliz modeli [ 25 ] ve insan kolesterol modeli [ 5 ] dahil olmak üzere artan karmaşıklığa sahip dinamik sistemlerin simülasyonları yoluyla veri üretiyoruz. Hem glikoliz modeli hem de kolesterol modeli in silico modeller. Bu in silico modeller, bir biyolojik sistemin gerçekçi modelleridir ve indüklenen varyasyonun farklı senaryolarını test etmeye olanak tanır. Gerçek verileri daha iyi taklit etmek için, denklemlerdeki kinetik parametreleri rastgele bozarak bu in silico modellere bireysel varyasyonu dahil ediyoruz ve ayrıca belirli parametrelerde bir azalma sağlayarak mutantları, yani indüklenen varyasyonu dahil ediyoruz. Simüle edilmiş verileri, Şekil 1’de gösterildiği gibi , özneler , metabolitler ve zaman modlarına sahip üç yönlü bir dizi olarak düzenliyoruz . Oluşturulan çok yönlü dizi daha sonra CANDECOMP/PARAFAC modeli olarak bilinen en popüler tensör modellerinden biri kullanılarak analiz edilir. CP modeli benzersiz olduğundan (permütasyon ve ölçekleme belirsizliklerine kadar) [ 13 , 27 ], diğer tensör modelleri yerine bu modeli seçtik, örneğin Tucker3 modeli [ 26 ]. Benzersizlik, dinamik metabolomik verileri analiz ederken önemli olan yorumlanabilir desenlere yol açar. Dahası, doğrusal olarak bağımlı faktörlerin varlığında gizli yapıyı CP modelinden daha iyi ortaya çıkarabildiğinden, kısıtlı bir CP modeli, yani Paralind (Doğrusal Bağımlılıklara Sahip Paralel Profiller) modelini [ 28 ] ele alıyoruz.
Yöntemler
Dinamik sistemler ve veri üretimi
Metabolit konsantrasyonlarının dinamikleri, aşağıdaki formdaki diferansiyel denklemlerle modellenebilir:
DXXDT=F(vv):=SSvv,XX(0)=XX0,(1)
Burada vektör metabolit konsantrasyonlarını temsil eder, türev metabolit konsantrasyonlarının zaman içindeki değişimini tanımlar, vektör metabolitler arasındaki reaksiyon akışlarını tanımlar ve matris metabolik ağı tanımlayan stokiyometrik matristir. Matristeki her satır bir metaboliti temsil eder, her sütun bir reaksiyona karşılık gelir ve her giriş, tüketilen metabolit ile negatif bir katsayı elde edilirken üretilen metabolit ile pozitif bir sayı verilecek bir reaksiyondaki bir metabolitin stokiyometrik katsayısını ifade eder. Vektör genellikle kinetik parametrelere sahip metabolitlerin konsantrasyonlarının bir fonksiyonudur.XXDXXDTvvSSSSvv
Doğrusal açık sistem
Akılar konsantrasyonların doğrusal fonksiyonları ise: , o zaman diferansiyel denklem şu şekilde yeniden yazılabilir: . 11 iç metabolit içeren doğrusal bir açık sistem oluşturuyoruz, burada ve boyutunda bir üç köşegen matristir . matrisindeki alt diyagonal elemanlar olarak ve süperdiyagonal elemanlar olması koşuluyla seçilir . Başlangıç değeri olarak ayarlanmıştır. Doğrusal açık sistem hakkında daha fazla ayrıntı Ek dosya 1’de bulunabilir : Bölüm 1. Verileri ürettiğimizde, simülasyonu [0, 0,2] dakikada ele alırız ve için zaman noktalarında çözümü seçeriz . Yol Ek dosya 1’de gösterilmiştir : Şekil S1.F(vv)=AAXX+BBDXXDT=AAXX+BBBB=103×[0,1,0,0,0,0,0,0,0,0,0,0]TAA11×11AA103×[0,2,0,1,0,5,0,3,2,1,3,0,4,1,0,4]T103×[0,3,0,5,2,2,0,3,3,0,5,1,0,2,0,4]TAA(11,11)=−103XX0=[1,1,1,1,1,1,1,1,1,1,1]T(6+5×k)×0,002k=0,1,…,19
Glikoliz modeli
Glikoliz modeli Van Heerden ve arkadaşları tarafından önerilmiştir [ 25 ] ve Denklem ( 1 )’deki doğrusal olmayan terim kinetik denklemleri tanımlayan parametreleri içerir. Bu model açık bir sistemdir ancak ek döngüler nedeniyle doğrusal açık sistemden çok daha karmaşıktır, örneğin metabolit FBP’den enzim PYK’ye ileri beslemeli kontrol döngüsü, ADP-ATP döngüsü ve Ek dosya 1’deki yol grafiğinde gösterilen NADH-NAD döngüsü : Şekil S3; bu model hakkında daha fazla ayrıntı Ek dosya 1’de bulunabilir : Bölüm 2. Verileri ürettiğimizde, [ 25 ]’te dikkate alınan varsayılan başlangıç değerlerini kullanırız. Simülasyonu [0, 0.2]dakikada ele alırızvvDipnot1içinzaman noktalarında çözümü seçin.(6+5×k)×0,002k=0,1,…,19
Kolesterol modeli
Kolesterol modeli van de Pas ve ark. tarafından önerildi [ 5 ] ve bu model için Denklem ( 1 )’deki doğrusal olmayan terim kinetik denklemlerdeki parametreleri içerir. Glikoliz modeline benzer şekilde, bu model de farklı kolesteroller arasında daha fazla döngüye sahip açık bir sistemdir; Ek dosya 1’deki yola bakın : Şekil S8. Model, örneğin ailevi hiperkolesterolemiye (FH), balık gözü hastalığına, Smith-Lemli-Opitz sendromuna (SLOS) ve diğer hastalıklara neden olan mutasyonlar dahil olmak üzere on bilinen mutasyona sahip verilerle doğrulandı [ 5 ]. Her mutasyon için, bazı belirli enzimler normal durumdan çok daha düşük aktivitelere sahiptir. Bu makalede, bu farklı mutant tiplerini indüklenen varyasyonların farklı kaynakları olarak ele alıyoruz. Verileri, [ 5 ] ‘tekiyle aynı başlangıç ayarlarını kullanarak modeli simüle ederek üretiyoruz , yani tüm normal denekler verilen başlangıç metabolit koşullarıyla başlıyor ve mutant denekler normal deneklerin sabit durum koşullarıyla başlıyor. Zaman noktalarını seçme şeklimiz şu şekildedir: [ 5 ]’te kullanılan zaman noktaları için, yani (logspace(0,6,1000)-1)vvDipnot2 , ilk zaman noktasından başlıyoruz ve toplamda 21 zaman noktası elde edene kadar her 24. zaman noktasını seçiyoruzDipnot3 .
Çok yönlü veri analizi
CANDECOMP/PARAFAC (CP) modeli
Bir tensörün poliadik formundan kaynaklanan CP modeli [ 30 ], 1970’te tanıtıldığından beri popüler hale gelmiştir [ 22 , 23 ]. CP çarpanlara ayırma, bir tensörü birinci rütbeli tensörlerin toplamı olarak gösterir (bkz. Şekil 1 ) ve matris Tekil Değer Ayrıştırması’nın (SVD) bir genellemesi olarak görülebilir. Üçüncü dereceden bir tensör in R bileşenli bir CP modeli aşağıdaki gibidir:XX∈RBEN×J×KXX
⟦⟧XX≈X^X^=⟦λλ;AA,BB,CC⟧:=∑R=1RλRAAR∘BBR∘CCR,
Burada birinci rütbe bileşenleri, sırasıyla faktör matrisleri olan ve vektörlerinden oluşmaktadır ve sütunlarıdır; bir skalerdir ve vektör dış çarpımını ifade eder. Bu tanımlamada, vektörü tarafından emildiği varsayılır . İki yönlü veri kümeleri için çoğu boyut indirgeme yönteminin aksine, CP modeli, ek kısıtlamalar getirmeden, hafif koşullar altında permütasyon ve ölçekleme belirsizliklerine kadar benzersizdir [ 13 , 27 ]. Benzersizlik, CP modelinin yorumlanabilir sonuçlar vermesini sağlar ve bu da onu yorumlanabilir veri analizi için çok tercih edilen bir araç haline getirir. Sonuçlar yorumlanırken, deneklerdeki faktör yüklemeleri , metabolitler ve zaman modları her bileşen için birlikte incelenmelidir.AAR,BBRCCRAA∈RBEN×R,BB∈RJ×RCC∈RK×RλR∘AA,BB,CCλλ
CP modeli , aşağıdaki optimizasyon problemini çözerek eksik girdileri olan verileri analiz etmek için de kullanılabilir [ 31 , 32 ]:
⟦⟧dakikaA,B,C‖BB∗(XX−⟦λλ;AA,BB,CC⟧)‖2,
Burada operatör Hadamard ürünüdür, girdileri aşağıdaki gibidir:∗‖.‖BB∈RBEN×J×K
wBenJk={1eğer XBenJk biliniyor,0eğer XBenJk eksik.(2)
Paralind modeli
En az bir modda doğrusal olarak bağımlı etkilere sahip varyasyonların temel kaynakları tarafından üretilen desenlere sahip üç yollu veriler için, en uygun CP modeli bu bağımlılıkları göstermelidir ve böyle bir çözüm rütbe eksiktir. Ancak, standart CP modeli verilerdeki gürültü nedeniyle gerçek gizli yapıyı ortaya çıkarmada başarısız olabilir [ 28 ]. Bunun yerine, başlangıçta kısıtlı bir Tucker modeli [ 33 ] olarak tanıtılan Paralind modeli [ 28 ] olarak adlandırılan özel bir CP modeli durumu daha uygundur. Bu model kısmen benzersizdir, yani yalnızca doğrusal olarak bağımsız faktör vektörlerine sahip faktörlerde benzersizliğe sahiptir ancak doğrusal olarak bağımlı faktörlerde benzersiz değildir. Verilerde bulunan örtük doğrusal bağımlılıkları açıkça temsil eder ve böylece gizli yapıyı daha doğru bir şekilde kurtarır. Ayrıca, Paralind modelinde daha az parametre kullanıldığından aşırı uyuma daha az eğilimlidir. İlk modda doğrusal olarak bağımlı faktörlere sahip Paralind modeli aşağıdaki gibi formüle edilebilir:
⟦⟧XX≈X^X^=⟦λλ;AA~,BB,CC⟧=∑R=1RλRA~R∘BBR∘CCR,
Burada ile ve , ve matrisi, doğrusal olarak bağımlı ilişkileri depolayan ‘bağımlılık matrisi’ olarak adlandırılır. Bu modeli Paralind( S , R , R ) ile gösteriyoruz . matrisi şu şekilde verilebilir:AA~=AAHHAA∈RBEN×SHH∈RS×RBB∈RJ×RCC∈RK×RHHHH
HH=[110001].
Sayısal deneyler
Bu bölümde, öncelikle veri setlerini oluşturmak için kullandığımız kurulumları sunacağız ve ardından CP ve Paralind modellerinin altta yatan mekanizmaları ve dinamikleri yakalama açısından performansını göstereceğiz.
Deneysel kurulum ve detaylar
Veri setlerini tanıtmadan önce, öncelikle bireysel ve indüklenen varyasyonları tanımlıyoruz.
- Bireysel varyasyon, sabit kinetik parametrelere eklenen rastgele bozulmaları ifade eder. Bireysel varyasyonun seviyesi ( ile gösterilir ) bozulmaların seviyesine bağlıdır. Doğrusal sistem için, bireysel varyasyon, örneğin %1’lik bir seviye içinde süperdiyagonal ve subdiyagonal elemanlara rastgele bozulmalar eklenerek tanıtılır.βDipnotVarsayılan değerlerden 4’ü) ve her sütunun toplamlarının sıfır olarak tutulması, ancakher zaman uygulanırβ=0,01AA(11,11)=−1×103Dipnot5. Glikoliz ve kolesterol modelleri için, kinetik parametrelerin belirli bir seviyesi içinde, örneğin varsayılan değerlerin %2’si içinde () rastgele bozulmalar eklenerek bireysel varyasyon tanıtılır.β=0,02
- İndüklenen değişim, belirli bir kinetik parametrede meydana gelen değişimi ifade eder ve indüklenen değişimin seviyesi ( ile gösterilir ) değişimin seviyesine bağlıdır.α
Aşağıdaki iki tür veri kümesini ele alacağız.
- Bir kaynaklı indüklenen varyasyona sahip veri kümesi. Bu tür veri kümesi 20 denek içerir:
- ( Normal denekler) İlk 10 denek, yalnızca seviyesinde bireysel varyasyonla simülasyonların çalıştırılmasıyla elde edilmiştir ;β
- ( Anormal seviyesinde bireysel varyasyon değerinin %50 oranında azalmasını sağlayan indüklenen varyasyon ile simülasyonlar çalıştırılarak elde edilir (bu denekleri anormal_ A (7,6) denekleri olarak gösteriyoruz ); glikoliz modeli için, VmaxPFK’nin varsayılan değerlerinde %50 oranında azalma vardırβAA(7,6) Dipnot6 (bu konular abnormal_VmaxPFK konuları olarak gösterilir ); kolesterol modeli için, mutant1 (kullanılarak (bu konular abnormal_mutant1 ile gösterilirα=0,62Dipnot(7 konu).
- İki kaynaklı indüklenen varyasyonlara sahip veri kümesi. Bu tür veri kümesi 30 denek içerir ve glikoliz ve kolesterol modelleri için üretilir:
- ( Normal denekler) İlk 10 denek, yukarıda açıklanan normal deneklerle aynı şekilde kullanılarak üretilir .β=0,02
- ( Anormal denekler) Bir sonraki 10 denek, glikoliz modelinde abnormal_VmaxPFK ( ) ve kolesterol modelinde abnormal_mutant6 ( dir .α=0,50α=0,35β=0,02
- ( Anormal denekler) Son 10 denek, glikoliz modelinde abnormal_VmaxPYK ( ) ve kolesterol modelinde abnormal_mutant10 ( değeri vardır .α=0,50α=0,95β=0,02
Her veri seti daha sonra özneler , metabolitler ve zaman modları ile üçüncü dereceden bir tensör olarak düzenlenir . Doğrusal açık sistem ve glikoliz modeli tarafından üretilen veri setleri, öznelerin sayısı × 11 metabolit × 20 zaman noktası boyutundadır ve kolesterol modeli tarafından üretilen veri setleri, öznelerin sayısı × 8 metabolit × 21 zaman noktası boyutundadır.
Veri ön işleme
Analizden önce, her üçüncü dereceden tensörü denek moduna göre merkezliyoruz [ 34 ]. Ayrıca, farklı metabolitlerin konsantrasyonları farklı aralıklarda olduğundan, tensör, metabolit modundaki her dilimin karekök ortalama değerine göre metabolit modunda ölçeklenir [ 34 ].
Model seçimi
Farklı modelleri değerlendirirken ve bileşen sayısını belirlerken, özellikle model uyumu, çekirdek tutarlılık tanısı, çapraz doğrulama ve Tucker’ın uyumluluk katsayısı olmak üzere çeşitli tanılamalar kullanırız. Model uyumu (genellikle açıklanan varyans olarak da adlandırılır ) şu şekilde tanımlanır:
Yerleştirmek=100×(1−‖XX−X^X^‖2‖XX‖2),
Burada ve sırasıyla orijinal verileri ve model tarafından veri yaklaşımını ifade eder. %100’lük bir uyum değeri, model tarafından tamamen açıklandığı anlamına gelirken, %100’den küçük bir uyum değeri, artıklarda açıklanamayan bir kısım kaldığı anlamına gelir. Farklı modeller (örneğin, farklı sayıda bileşene sahip modeller) için model uyumunda belirgin bir değişiklik, daha iyi bir model peşinde koşarken dikkate alınması gereken önemli bir kazanımı gösterir.XXX^X^XX
Çekirdek tutarlılık teşhisinin ayrıca bir CP modelindeki bileşen sayısını belirlemek için de yararlı olduğu gösterilmiştir [ 35 ]. Bir CP modelinin çekirdek tutarlılığı, çekirdek dizisinin süperdiyagonallik derecesinin karşılaştırılmasıyla tanımlanırDipnotCP modelinin 8’i ve CP faktörlerini kullanarak Tucker3 modeliyle [ 26 ] verilerin modellenmesiyle elde edilen çekirdek dizisi. %100’e yakın çekirdek tutarlılık değeri uygun bir modeli gösterir ve çok fazla bileşen kullanılırsa düşmesi beklenir.
Son olarak, model seçimi için çapraz doğrulama yoluyla eksik veri tahmin performansını kullanırız. Daha kesin olarak, verilere biraz gürültü ekleriz, yani,
XXgürültü=XX+ηNN‖XX‖‖NN‖,
burada girişleri standart normal dağılımdan rastgele çekilen üçüncü dereceden bir tensördür ve gürültü seviyesidir. Tensör girişlerinin %20’sini rastgele eksik olarak ayarladık, verileri önceden işledik ve eksik girişleri kurtarmak için farklı modeller (yani, CP ve Paralind) kullandık. Farklı rastgele eksik giriş kümelerini kullanarak yöntemlerin performansını değerlendirmek için bu işlemi 20 kez tekrarladık. Daha sonra farklı modellerin performansı, [ 31 ] olarak tanımlanan tensör tamamlama puanı (TCS) kullanılarak değerlendirildiNNη
TÇS=‖(1−BB)∗(XX^−XXgürültü)‖‖(1−BB)∗XXgürültü‖,
Burada Denklem ( 2 ) ile tanımlanır . TCS, bir model için test hatasının bir değerlendirmesi olarak görülebilir ve daha düşük bir değer, modelin verilerdeki temel kalıpları yakalamada daha iyi davrandığını gösterir.BB
CP modelleri iki faktörlü bir dejenerasyondan muzdarip olabilir (dejenerasyon hakkında daha fazla ayrıntı için [ 36 ]’ya bakın). Modelin iki faktörlü bir dejenerasyona sahip olup olmadığını değerlendirmek için Tucker’ın uyumluluk katsayısını (TC ile gösterilir) kullanırız [ 37 ]. i’inci ve j’inci bileşen için TC değeri şu şekilde tanımlanır:
TCBenJ=AABenTAAJ‖AABen‖‖AAJ‖BBBenTBBJ‖BBBen‖‖BBJ‖CCBenTCCJ‖CCBen‖‖CCJ‖,
Bu, her moddaki iki bileşenin kosinüs benzerliğinin ( ) çarpımına karşılık gelir. Bu makalede, TC değerini olarak alıyoruz; burada . – 1’e yakın bir TC değeri, geçerli bir model olmayan dejeneratif bir modeli gösterir.CBenJ=AABenTAAJ‖AABen‖‖AAJ‖TC=TCBen0J0|TCBen0J0|=maksimumBen,J|TCBenJ|
Uygulama detayları
CP modelleri , Tensor Toolbox sürüm 3.1’den [ 39 ] cp-opt [ 38 ] ve cp-wopt [ 31 ] (eksik girişleri olan verilere) kullanılarak , sınırlı bellekli BFGS (LBFGS-B) kullanılarak uygulanırDipnot9 optimizasyon algoritması olarak. Zaman modunda negatif olmayan kısıtlamayı uygularız. Paralind modeliDipnot10, Bro ve diğerleri tarafından tanıtılan algoritma kullanılarak yerleştirilir [ 28 ]. Benzersiz modeller elde etmek için, Paralind modelini yerleştirirken metabolitler modunda faktör matrisinin ortogonal ve zaman modunda negatif olmayan olmasını zorunlu kılıyoruz. Yerel minimumlardan kaçınmak için çoklu rastgele başlatmalar kullanılır. Çekirdek tutarlılığının hesaplanması için, N-yollu araç kutusundan corcond fonksiyonunu kullanırız [ 40 ]. Tüm deneyler MATLAB’da (2020a sürümü) gerçekleştirilir.
Sonuçlar ve tartışmalar
Doğrusal açık sistem
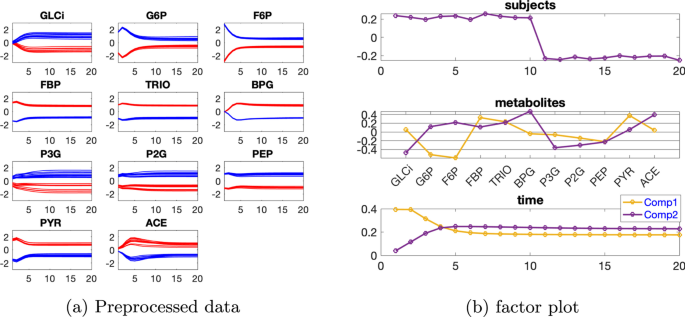
Tek kaynaklı indüklenmiş varyasyona sahip veri kümesi İndüklenmiş varyasyonu varsayılan değer olanve bireysel varyasyonu. Öncelikle verilerin bir CP modeli kullanılarak analizini ele alıyoruz. Tablo 1’den , çekirdek tutarlılığının 2 bileşenli modelden 3 bileşenli modele doğru keskin bir şekilde düştüğünü görebiliyoruz. Bu, 2 bileşenli bir modelin daha uygun olabileceği anlamına geliyor. Ancak, 2 bileşenli CP modeli için denek modunda sıralama eksikliği gözlemleniyor ( denek modundaki bileşenlerinbenzerlik puanı. Bu, verilerin gerçekten bir Paralind(1,2,2) modelini izlediğini ve Şekil 2’de gösterilen çapraz doğrulama performansının, Paralind(1,2,2) modelinin, dışarıda bırakılan verileri kurtarmada 2 bileşenli CP modelinden daha iyi olduğunu göstermektedir.AA(7,6)β=0,01C12=1.00Tablo 1 Açıklanan varyans (uyum), çekirdek tutarlılık (CC), Tucker’ın uyumluluk katsayısı (TC), kosinüs benzerlik puanı ( ) denek modunda ve bileşen sayısı ( R ) doğrusal açık sistem tarafından üretilen verileri analiz etmek için kullanılan CP modelleri için tek kaynaklı indüklenmiş varyasyon ve bireysel varyasyon düzeyindeC12β=0,01
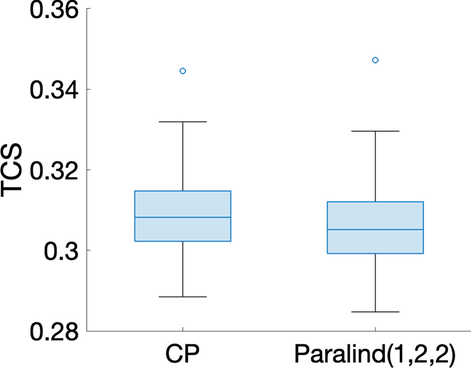
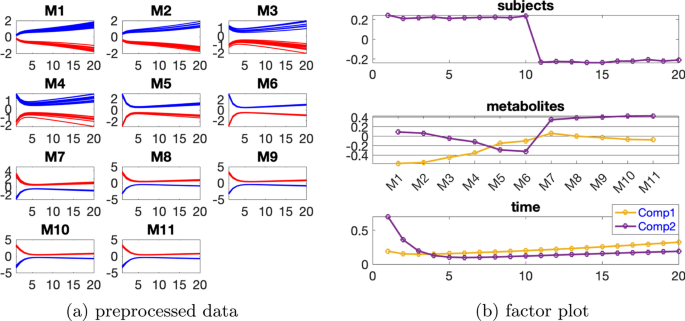
Paralind(1,2,2) modeli verilerin %98,38’ini açıklıyor ve bu, ekstra kısıtlama nedeniyle CP modelinden biraz daha düşük. Paralind(1,2,2) modelinin özne modu, iki grup arasında net bir ayrım gösteriyor (Şekil 3 b). Metabolitler modundaki ilk bileşenden (Şekil 3 b), M1 , M2 , M3 ve M4 metabolitlerinin büyük mutlak katsayılara sahip olduğunu ve zaman modunda ilk bileşenin bu metabolitlerde gösterilen dinamikleri yakaladığını gözlemliyoruz . Bu bileşen için kalan metabolitlerin katsayıları sıfıra yakındır. İkinci bileşen için, tam tersi şekilde, M7 , M8 , M9 , M10 , M11 ve M5 , M6 metabolitleri büyük katsayılara sahiptir ve bu metabolitlerde gösterilen dinamikler, zaman modunda ikinci bileşen tarafından yakalanır. Ayrıca, metabolitler modundaki her iki bileşenden (Şekil 3 b), Şekil 3 a’da gösterilen bu iki metabolit arasındaki mavi ve kırmızı çizgilerin yer değiştirmesiyle tutarlı olan, metabolitler M6 ve M7 arasında bir sıçrama değişimi gözlemliyoruz . Bu değişim, anormal_ A (7,6) deneklerinde nın azalmasından kaynaklanmaktadır ve değişimin model tarafından başarılı bir şekilde yakalanması, Şekil 3 b’de görüldüğü gibi, denek modunda normal (ilk 10 denek) ve anormal_ A (7,6) (son 10 denek) gruplarının başarılı bir şekilde ayrılmasıyla sonuçlanır .AA(7,6)
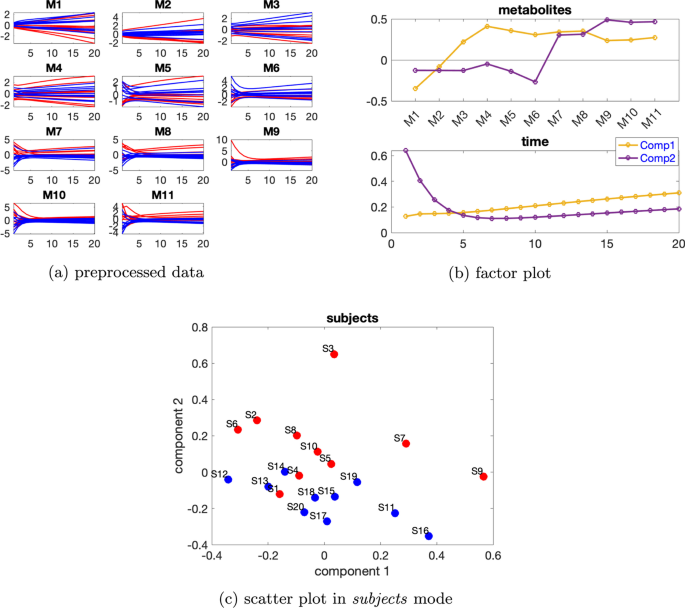
Daha büyük bireysel varyasyon dikkate alındığında, rütbe eksikliği ortadan kalkar ve CP modelleri altta yatan örüntüleri daha iyi yakalar, örneğin bkz. Şekil 4 , burada bireysel varyasyon seviyesi ve 2 bileşenli CP modeli için denek modundaki iki bileşenin benzerlik puanı ‘tür . CP modeli verilerin %62,42’sini açıklar. Şekil 4b’de sunulan metabolitler ve zaman modlarındaki ilk bileşenden, M2 hariç tüm metabolitlerin büyük mutlak değerlere sahip katsayılara sahip olduğunu ve zaman modundaki bileşenin tüm metabolitlerde görülen dinamiği bir dereceye kadar yakaladığını gözlemliyoruz. Metabolitler modundaki ikinci bileşenden ( 4b ), M6 , M7 , M8 , M9 , M10 ve M11 metabolitlerinin büyük katsayılara sahip olduğunu ve zaman modunda bu bileşenin bu metabolitlerde gösterilen hızlı düşüşü yakaladığını gözlemliyoruz . M9 , M10 ve M11’deki dinamikler esas olarak ikinci bileşen tarafından yakalanır, ancak metabolitler M5 , M6 , M7 ve M8’deki dinamikler, Şekil 4a’da gösterildiği gibi, zaman modunda iki bileşenin bir karışımıdır . Ayrıca, Şekil 3b’de gösterilen sıçrama değişimine benzer şekilde, metabolitler modunda ikinci bileşende metabolitler M6 ve M7 arasında bir sıçrama değişimi gözlemliyoruz ( 4b ). Bu , Şekil 4a’da gösterilen metabolitler M6 ve M7’deki mavi ve kırmızı çizgilerin değişimiyle tutarlıdır ve anormal_ A (7,6) deneklerinde ‘nın azalmasından kaynaklanmaktadır . Bu nedenle, denek modundaki ikinci bileşenin, Şekil 4c’de gösterildiği gibi, normal ve anormal_ A (7,6) denekleri bir dereceye kadar ayırabilmesi makuldür.β=0,3C12=−0,24AA(7,6)
Yardımcı deneyler, CP modellerinin davranışının kinetik katsayılara dayandığını göstermektedir. Bazı özel durumlar için, CP modelleri için dejenerasyon gözlemlenmiştir, örneğin, ayarı ve köşegen elemanlarının 1 , 1, 1, 1, 1, 1]\) olarak ayarlandığı bir üç köşegen matris \({\varvec{{A}}} . Böyle bir ayar ve küçük bir bireysel varyasyonla doğrusal açık sistem tarafından üretilen veriler için, örneğin, , CP modeli dejeneratiftir. Ancak, Paralind modeli bu gibi durumlarda da yararlıdır ve altta yatan dinamikleri yakalar; bkz. Ek dosya 1 : Şekil S2.BB=103×[0,5,0,0,0,0,0,0,0,0,0,0]TAA103×[−1,−2,−2,−2,−2,−2,−2,−2,−2,−2,−2]103×[1,1,1,1,1,1,1,1,1,1]β=0,01
Glikoliz modeli
Tek kaynaklı indüklenen varyasyona sahip veri seti
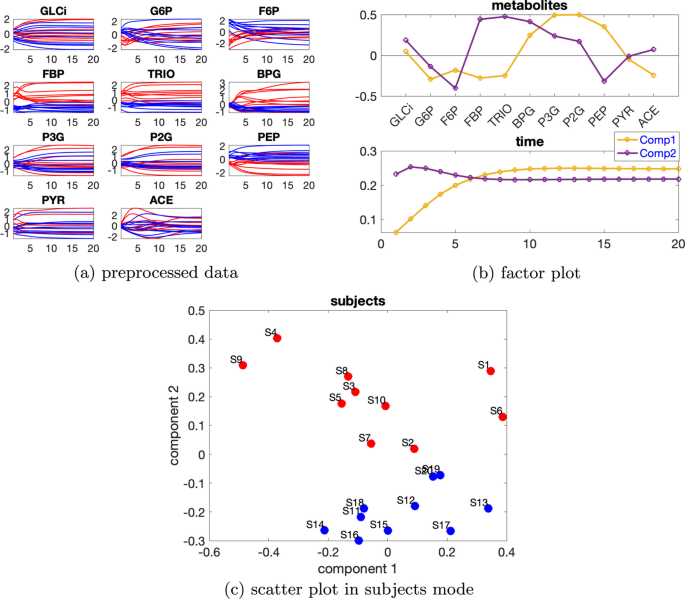
Veriyi, VmaxPFK’nin varsayılan değerinin %50 azalması ve bireysel varyasyonu seviyesindeki indüklenmiş varyasyon olarak ele alıyoruz. Her bir metabolitin zamansal profilleri Şekil 5a’da gösterilmiştir . Tablo 2’ye dayanarak , 2 bileşenli bir CP modeli kullanıyoruz ve doğrusal açık sistemde olduğu gibi, denek modunda rütbe eksikliği gözlemliyoruz . Rütbe eksikliğini hesaba katmak için, bu veri setini analiz etmek için bunun yerine bir Paralind(1,2,2) modeli kullanıyoruz. CP’nin Paralind’e karşı çapraz doğrulama performansı, verilerin %96,05’ini açıklayan Paralind(1,2,2) modelinin bu veri seti için daha iyi bir seçim olduğunu da gösteriyor (bkz. Ek dosya 1 : Şekil S4). İki denek grubu iyi ayrılabilir ve doğrusal sistemle karşılaştırıldığında, Şekil 5b’de gösterilen metabolit modundaki faktör grafiği, ağın karmaşıklığı nedeniyle daha karmaşıktır. β=0,02Tablo 2 Açıklanan varyans (uyum), çekirdek tutarlılık (CC), Tucker’ın uyumluluk katsayısı (TC), ilk iki bileşenin kosinüs benzerlik puanı ( ) denek modunda ve bileşen sayısı ( R ) glikoliz modeli tarafından üretilen verileri analiz etmek için kullanılan CP modelleri için tek kaynaklı indüklenmiş varyasyon ve bireysel varyasyon düzeyindeC12β=0,02
İlk bileşen, Şekil 5a’da gösterilen bu metabolitler arasındaki mavi ve kırmızı çizgilerin yer değiştirmesiyle tutarlı olan ve VmaxPFK’nin azalmasından kaynaklanan, biri F6P ve FBP metabolitleri arasında, diğeri PEP ve PYR metabolitleri arasında olmak üzere iki büyük sıçrama değişikliği olduğunu göstermektedir . F6P ve FBP metabolitleri arasındaki değişiklik, Şekil 3’te doğrusal açık sistem için gösterilen değişikliğe benzer şekilde , doğrudan VmaxPFK’nin azalmasına karşılık gelir. PEP ve PYR metabolitleri arasındaki değişiklik, VmaxPFK’nin azalması ve yol grafiğinde gösterilen ileri beslemeli kontrol döngüsünün neden olduğu FBP azalmasından kaynaklanan VmaxPYK enziminin aktivitesinin azalmasına karşılık gelir (Ek dosya 1 : Şekil S3). Metabolitler G6P , F6P , FBP ve PYR ilk bileşende büyük mutlak katsayılara sahiptir ve bu metabolitlerde gösterilen üçüncü zaman noktalarından gelen dinamikler, Şekil 5b’de gösterildiği gibi, zaman modunda ilk bileşen tarafından iyi yakalanmıştır. Metabolitler FBP ve PYR’de gösterilen çıkıntılar, zaman modunda iki bileşenin doğrusal kombinasyonları tarafından yakalanabilir. Ek bir bileşene sahip modeller, örneğin Ek dosya 1’de gösterildiği gibi G6P’deki çıkıntı gibi daha fazla varyansı yakalamak için yararlı olacaktır : Şekil S5. Ancak, dinamik varyasyonların çoğunu yakaladığı ve yorumlanması daha kolay olduğu için Paralind (1,2,2) modelini kullanmayı tercih ediyoruz.
Metabolitler modundaki ikinci bileşen, Şekil 5a’da gösterilen mavi ve kırmızı çizgilerin geçişiyle tutarlı olan metabolitler BPG ve P3G arasında bir sıçrama değişimini gösterir. Bu geçiş, VmaxPYK reaksiyon hızının düşmesiyle oluşan PEP , P2G ve P3G artışından kaynaklanır.Dipnot11 ve anormal_VmaxPFK denekleri için VmaxPFK’nin azalması nedeniyle FBP , TRIO ve BPG’nin azalması. Metabolitler GLCi , BPG ve ACE ikinci bileşende büyük mutlak puanlara sahiptir ve bu metabolitlerin dinamikleri, Şekil 5b’de gösterildiği gibi zaman modunda ikinci bileşen tarafından iyi yakalanmıştır . Metabolitler TRIO , P3G , P2G ve PEP’de gösterilen dinamikler , zaman modunda her iki bileşenin bir karışımıdır.
Daha yüksek düzeyde bireysel varyasyon düşünüldüğünde, özneler modundaki doğrusal bağımlılık zayıflar, örneğin bkz. Ek dosya 1 : Tablo S1, burada bireysel varyasyon düzeyi ve özneler modundaki iki bileşenin kosinüs benzerlik puanı 2 bileşenli bir CP modeli için dir . Bu nedenle Paralind modelleri yerine CP modelleri tercih edilir. Ek dosya 1 : Tablo S1’den, çekirdek tutarlılık değerleri 2 veya 3 bileşenli bir modelin kullanıldığını göstermektedir. 3 bileşenli modeldeki ek faktör yararlı bilgi sağlamadığından 2 bileşenli CP modelini seçtik. 2 bileşenli CP modeli verilerin %54,12’sini açıklıyor. Metabolitler ve zaman modundaki ilk bileşenden (bkz. Şekil 6b ), P3G , P2G ve PEP metabolitlerinin büyük katsayılara sahip olduğunu ve Şekil 6a’da gösterildiği gibi bu metabolitlerin dinamiklerinin yakalandığını gözlemliyoruz. Metabolitler modundaki ikinci bileşenden (bkz. Şekil 6b ), F6P , FBP , TRIO ve BPG metabolitlerinin büyük mutlak katsayılara sahip olduğunu ve bu metabolitlerin çoğunda mavi ve kırmızı çizgilerin ayrılabilir olduğunu gözlemliyoruz . Bu, Şekil 6c’de gösterildiği gibi, normal ve abnormal_VmaxPFK denekleri arasında ikinci bileşen tarafından denek modunda gözlemlenen ayrımla tutarlıdır. Zaman modundaki ikinci bileşen, bu metabolitlerdeki bazı deneklerin gösterdiği dinamikleri yakalar (Şekil 6a ).β=0,36C12=−0,28
Daha da büyük bireysel varyasyona sahip veriler için, CP modelleri grupları ayıramayabilir. Başarısızlık, (i) bireysel varyasyonun varyansa hakim olmasından kaynaklanır, örneğin Ek dosya 1’e bakın : Şekil S6, burada bireysel varyasyon seviyesi, indüklenen varyasyona eşittir ( ), (ii) bir veya iki deneğin kendine özgü davranış gösterme olasılığı olan sınırlı sayıda denek ( Ek dosya 1’deki BPG profillerine bakın : Şekil S6a) ve böylece ortaklık çıkarmak zorlaşır. Gerçekten de, denek sayısı daha fazla olduğunda (Ek dosya 1’e bakın : Şekil S7), verilerin %66,56’sını açıklayan 3 bileşenli CP modeli, verilerdeki ana değişimi ( VmaxPFK’nin azalması) yakalayabilir ve normal ve anormal_VmaxPFK için bile başarıyla ayırabilir . İdiopatik davranışların daha yaygın hale gelmesi, modellemeyi kolaylaştırmıştır.β=α=0,50β=α=0,50
İki kaynaklı indüklenen varyasyona sahip veri setiseviyesindeki bireysel varyasyonve iki kaynaklı indüklenen varyasyon ile üretilen verileri VmaxPFK için varsayılan değerin %50 azalması ve VmaxPYK için varsayılan değerin %50 azalması. Tablo 3, verilerin %88,68’ini açıklayan 2 bileşenli bir CP modelinin kullanıldığını göstermektedir.β=0,02Tablo 3 Açıklanan varyans (uyum), çekirdek tutarlılık (CC), Tucker’ın uyumluluk katsayısı (TC), ilk iki bileşenin kosinüs benzerlik puanı ( ) denek modunda ve bileşen sayısı ( R ) glikoliz modeli tarafından üretilen verileri analiz etmek için kullanılan CP modelleri için VmaxPFK’de %50 azalma ve VmaxPYK’de %50 azalma olarak iki kaynaklı indüklenmiş varyasyon ve ayrıcaC12β=0,02
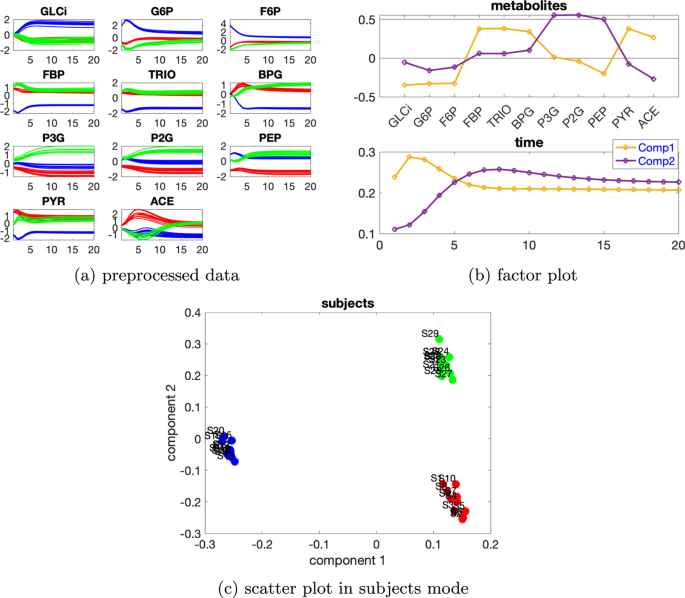
Metabolitlerdeki ve zaman modundaki ilk bileşenden (bkz. Şekil 7b ), GLCi , G6P , F6P , FBP , TRIO , BPG , PYR ve ACE metabolitlerinin büyük mutlak katsayılara sahip olduğunu ve Şekil 7a’da gösterilen bu metabolitlerin çoğundaki dinamiklerin yakalandığını gözlemliyoruz. Ayrıca, Şekil 7a’da gösterildiği gibi, mavi çizgiler bu metabolitlerdeki diğer çizgilerden ayrılabilir . Bu, denek modundaki ilk bileşenin (Şekil 7c ) abnormal_VmaxPFK deneklerini diğerlerinden ayırdığı gözlemiyle tutarlıdır. Dahası, Şekil 7a’daki VmaxPFK azalması ve ileri beslemeli kontrol döngüsü nedeniyle mavi çizgilerin diğer çizgilerle yer değiştirmesine uygun olarak, F6P ve FBP metabolitleri ile PEP ve PYR arasında bir sıçrama değişimi gözlemliyoruz . Bu gözlemler, Şekil 5 a, b’de glikoliz modeli için bir kaynaklı indüklenen varyasyon için fark edilenlere benzerdir . Metabolitler ve özneler modundaki ikinci bileşenden (bkz. Şekil 7 b, c), P3G , P2G ve PEP metabolitlerinin büyük puanlara sahip olduğunu ve üç tür öznelerin birbirinden ayrılabileceğini görüyoruz . Bu, Şekil 7 a’da gösterildiği gibi , P3G ve P2G metabolitlerinde farklı renklerde çizgilerin ayrılabilmesi nedeniyle mantıklıdır. Dahası, metabolitler modunda bu bileşende PEP ve PYR metabolitleri arasında bir sıçrama değişimi gözlemliyoruz . Bu, Şekil 7 a’da gösterilen diğer çizgilerle yeşil çizgilerin yer değiştirmesiyle uyumludur ve VmaxPYK’nin azalmasından kaynaklanmaktadır . Zaman modunda, P3G ve P2G metabolitlerinde gösterilen dinamiklerin ikinci bileşen tarafından yakalandığını gözlemliyoruz .
Kolesterol modeli
Tek kaynaklı indüklenmiş varyasyona sahip veri seti İndüklenmiş varyasyona sahip verileri mutant1 ve bireysel varyasyonu. Önceden işlenmiş verilerin zamansal profilleri Şekil 8a’da gösterilmiştir . Ek dosya 1 : Tablo S2, 2 veya 3 bileşenli bir modelin kullanıldığını gösterir ve hem iki hem de üç bileşene sahip CP modelleri için denek modunda rütbe eksikliği gözlemlenirβ=0,02
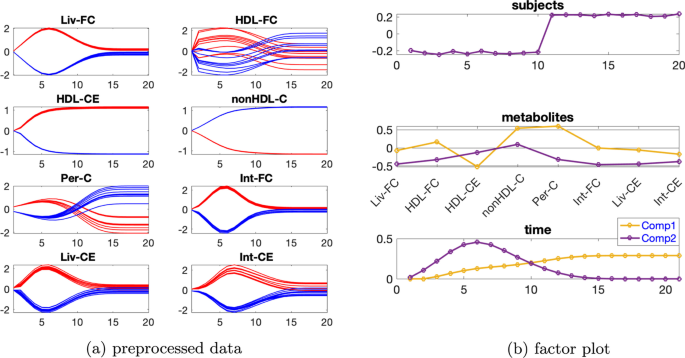
Bu nedenle Paralind modelini kullanıyoruz ve yorumdan, 2 bileşenli bir modeli tercih ediyoruz. Dahası, çapraz doğrulama performansı (Ek dosya 1 : Şekil S9), Paralind(1,2,2) modelinin 2 bileşenli CP modelinden daha iyi davrandığını göstermektedir. Paralind(1,2,2) modeli verilerin %89,10’unu açıklamaktadır. Özneler modundaki faktör grafiğinden ( Şekil 8 b), normal ve abnormal_mutant1 özneleri arasında net bir ayrım görüyoruz . Metabolitler ve zaman modundaki ilk bileşenden (bkz. Şekil 8 b), HDL-CE , nonHDL-C ve Per-C metabolitlerinin büyük katsayılara sahip olduğunu, kalan metabolitlerin katsayılarının ise sıfıra yakın olduğunu gözlemliyoruz ; zaman modundaki bileşen, metabolit nonHDL-C’de gösterilen dinamikleri ve ayrıca Şekil 8 a’da gösterildiği gibi HDL-CE ve Per-C metabolitlerindeki dinamiklerin bir karışımını yakalar . Ayrıca, Şekil 8a’daki mavi ve kırmızı çizgilerin yer değiştirmesiyle tutarlı olan metabolitler HDL-CE ve nonHDL-C arasında net bir sıçrama değişimi gözlemliyoruz ve bu, mutant1’in neden olduğu abnormal_mutant1 denekleri için metabolitler nonHDL-C’nin yükselmesi ve metabolitler HDL-CE’nin azalmasından kaynaklanmaktadır. Metabolitler ve zaman modundaki ikinci bileşenden (bkz. Şekil 8b ), Liv-FC , Int-FC , Liv-CE ve Int-CE metabolitlerinin büyük katsayılara sahip olduğunu ve zaman modundaki bileşenin , Şekil 8a’da gösterildiği gibi, bu metabolitlerde gösterilen ortak dinamikleri yakaladığını görüyoruz ; ayrıca, Şekil 8a’da gösterilen mavi ve kırmızı çizgilerin yer değiştirmesiyle tutarlı olan metabolitler nonHDL-C ve Per-C arasında bir sıçrama değişimi gözlemliyoruz .
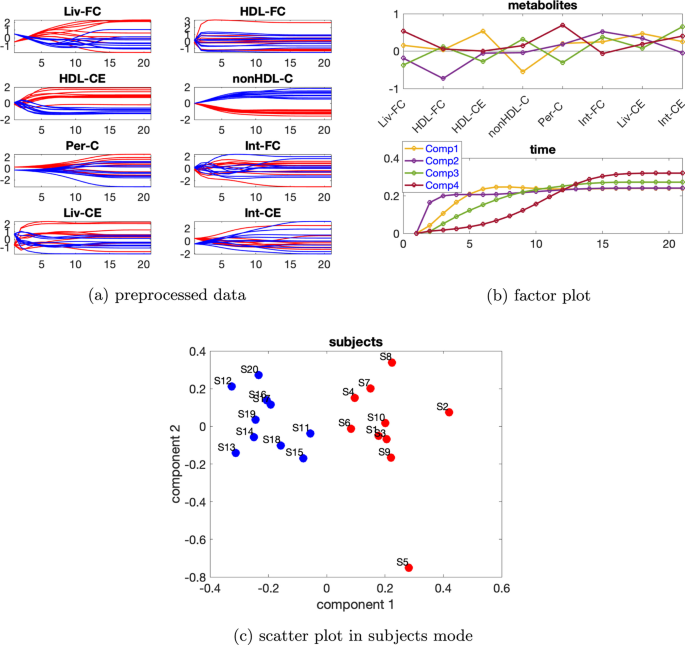
Bu değişim aynı zamanda mutant1’den de kaynaklanmaktadır çünkü nonHDL-C’den Liv-FC ve Per-C’ye olan reaksiyon hızı azalır ve bu da nonHDL-C’nin artmasına ve Per-C’nin azalmasına yol açar .
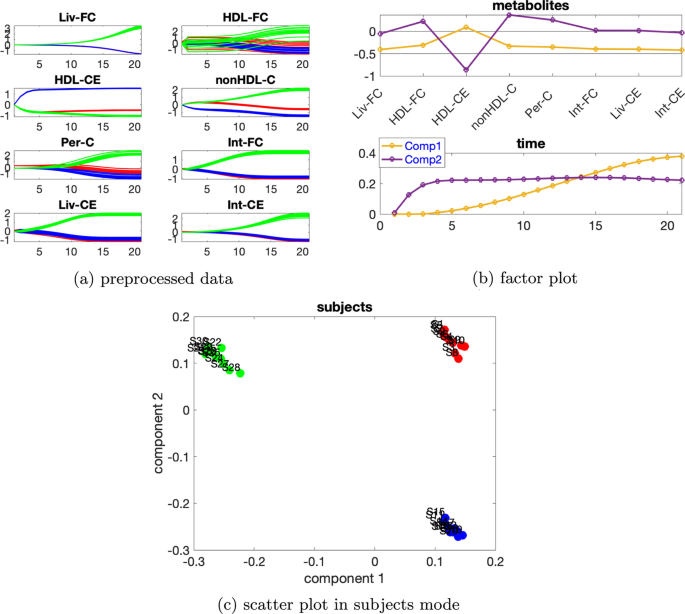
Yüksek düzeyde bireysel varyasyonlar dikkate alındığında, denekler modundaki rütbe eksikliği ortadan kalkar ve CP modelleri tercih edilir. düzeyinde bireysel varyasyona sahip verileri ele alıyoruz. Ek dosya 1 : Tablo S3’e dayanarak , verilerin %79,15’ini açıklayan 4 bileşenli bir CP modeli kullanıyoruz. Metabolitlerdeki ve zaman modundaki ilk bileşenden (bkz. Şekil 9 a), HDL-CE ve nonHDL-C metabolitlerinin en büyük mutlak katsayılara sahip olduğunu ve Şekil 9 b’de gösterildiği gibi metabolit HDL-CE’deki dinamiklerin yakalandığını gözlemliyoruz . Ek olarak, Şekil 9 c’de denekler modundaki ilk bileşenin normal ve abnormal_mutant1 denekleri ayırdığını görüyoruz . Bu mantıklıdır çünkü mavi ve kırmızı çizgiler Şekil 9 a’da gösterildiği gibi metabolitler HDL-CE ve nonHDL-C’de ayrılabilir. Zaman modundaki ikinci bileşen, metabolitler modunda ikinci bileşende en önemli mutlak puanı alan metabolit HDL-FC’de gösterilen dinamikleri yakalar . Üçüncü bileşen, metabolitler modunda üçüncü bileşende en büyük pozitif puanı alan metabolit Int-CE’de gösterilen dinamikleri yakalar ve dördüncü bileşen , metabolitler modunda dördüncü bileşende en büyük pozitif puanı alan metabolit Per-C’de gösterilen dinamikleri yakalar .β=0,65
İki kaynaklı indüklenmiş varyasyona sahip veri kümesi Bireysel varyasyonla[ 5 ]’teki mutant6 ve mutant10 olarak iki kaynaklı indüklenmiş varyasyonu. Ek dosya 1 : Tablo S4, 2 bileşenli bir modelin kullanıldığını gösteriyor. İki bileşenli CP modeli verilerin %91,89’unu açıklıyor.Şekil 10c’de gösterilen denek modundan , ilk bileşenin abnormal_mutant10 deneklerini kalan deneklerdenayırdığını , ikinci bileşenin ise normal denekleri abnormal_mutant6 deneklerinden ayırdığını gözlemliyoruz. Bu mantıklıdır çünkü HDL-CE hariç tüm metabolitlerin metabolit modunda ilk bileşen üzerinde büyük bir katsayıları vardır ve Şekil 10a’dan bu metabolitler için önceden işlenmiş verilerdeki mavi çizgilerin ve kırmızı çizgilerin oldukça yakın olduğunu ve yeşil çizgilerden açıkça ayrıldığınıgörebiliriz Metabolit HDL-CE ikinci bileşende en büyük mutlak puana sahipken ve mavi çizgiler,Şekil 10 a’da gösterildiği gibi metabolit HDL-CE için diğer çizgilerden açıkça ayrılabilir. Metabolitlerdeki ve zaman modundaki grafikleri birleştirdiğimizde (Şekil 10 b), modelin iki ana tür dinamiği yakaladığını gözlemliyoruz, yani metabolit HDL-CE’de gösterilen sabit duruma (ikinci bileşen) hızla artanve kalan metabolitlerin çoğunda gösterilen sabit duruma (birinci bileşen) doğru yavaşça artan.β=0,02
Çözüm
Bu makalede, dinamik sistemlerin simülasyonları yoluyla üretilen dinamik metabolomik verilerinin analizi için tensör faktörizasyonlarını inceledik. CP ve Paralind modeli de dahil olmak üzere bu tür yöntemlerin temel fikri, konular arasındaki ortaklığı, yani ortak dinamik davranışları çıkarmaktır. Pratikte karşılaşılan metabolik sistemlerin dinamik davranışı (i) farklı varyasyon kaynaklarının boyutlarına ve (ii) sistemin kendisinin yapısına, yani metabolik ağın topolojisinin yanı sıra kinetik sabitlerin boyutlarına bağlıdır. Artan karmaşıklığa sahip dinamik sistemleri, yani doğrusal açık bir sistem, bir maya glikoliz modeli ve bir insan kolesterol modeli kullanarak, sistemin yapısını ve farklı varyasyon kaynaklarını inceledik ve CP ve Paralind modellerinin farklı ortamlarda altta yatan dinamikleri ne kadar iyi yakaladığını gösterdik. İncelediğimiz yeterli ortaklığın olduğu tüm durumlarda, üç yollu verileri nispeten basit çok yollu modellerle, yani CP ve Paralind modelleriyle modelleyebiliriz. Bu modeller, metabolitler arasındaki ilişkilerdeki değişikliklerin başarılı bir şekilde yakalanmasıyla yansıtılan verilerdeki müdahaleleri tespit etmeyi başarır; bu, metabolitlerin faktör grafiklerindeki sıçrama değişiklikleriyle gösterilir. Metabolik ağ (topoloji ve bağlantı güçleri) ile CP veya Paralind modellerindeki metabolitlerin faktör yüklemeleri arasındaki ilişkinin ayrıntılı bir açıklaması, takip araştırmasının konusudur. Çoğu durumda, altta yatan silico modelden çıkarılan kalıpları da açıklayabilir ve anlayabiliriz. Ancak, dinamik davranıştaki bireysel farklılıklar pratikte, örneğin meydan okuma testlerinde muazzam olabilir [ 41 ]. Bu, örneklenen sınırlı sayıda bireyde, kendine özgü davranışa sahip bazılarının olacağı anlamına gelir. Deneylerimizde, bu kendine özgü davranışın daha çok bir yetersiz örnekleme sorunu olduğunu gösterdik.
CP ve Paralind modeli arasındaki seçim veri özelliklerine bağlıdır ve bu da, yukarıdaki paragrafta tartışılan (i) ve (ii) iki yönüne bağlıdır. Bu makalede, pratikte uygun bir model seçmek için iyi tanılamalar sunuyoruz. Küçük bireysel varyasyona sahip veriler ve dinamik davranış üzerinde benzer etkilere sahip indüklenen varyasyon kaynakları için Paralind modelini kullanıyoruz (CP modelindeki doğrusal bağımlılık faktörleri nedeniyle); büyük bireysel varyasyona sahip veriler veya çeşitli indüklenen varyasyonlara sahip veriler için CP modellerinin iyi çalıştığını gösteriyoruz.
Gecikmeli dinamik sistemler veya indüklenen varyasyondaki önemli farklılıklardan dolayı farklı dinamiklere sahip sistemler veya büyük kendine özgü davranışlar gibi daha karmaşık durumlar için, PARAFAC2 [ 42 ] veya Sınırlı Tucker [ 33 ] gibi daha karmaşık çok yönlü modellere ihtiyaç duyabiliriz. Ayrıca, zamanla evrimleşen metabolitlerle ilgilendiğimiz durumlar için [ 10 ], PARAFAC2’nin metabolitler modunda evrimleşen faktör matrislerini yakalayarak bunları ortaya çıkarması beklenir . Ayrıca, bireyler arasındaki rastgele varyasyonu hesaba katan karışık etkili üç yönlü modelleri dikkate almaya değer olabilir.
Bu simülasyon çalışması gerçek bir dinamik metabolomik veri setinin analizinden ilham almıştır. Gerçek verilerde, altta yatan dinamik ağ bilinmemektedir ve veri seti boyutu daha büyüktür, örneğin, metabolit ve denek sayısı yüzlerce mertebesindedir. CP modellerinin hala varyasyonların ana modellerini ve karşılık gelen zamansal profilleri ortaya çıkarması beklenmektedir, bunu gerçek bir metabolomik meydan okuma testi veri setindeki bulgularımızla göstermeyi planlıyoruz. Gelecekte bu tür büyük ölçekli dinamik metabolomik veri setleri mevcut olacaksa, yöntemler daha büyük veri setlerine [ 43 , 44 ] (her modda binlerce veya daha fazla değişkenle) de ölçeklenebilir.
Bu makalede yalnızca dinamik metabolomik verilerin analizine odaklansak da, gelecekteki çalışmalar, tensör faktörizasyonlarının eşleştirilmiş matris ve tensör faktörizasyonlarına [ 46 ] genişletilmesi yoluyla birden fazla omik veri setinin ortak analizini içermektedir [ 45 ] .
Veri ve materyallerin kullanılabilirliği
Makalede kullanılan veri kümeleri ve veri kümelerini analiz etmek için kullanılan örnek betikler Github deposunda mevcuttur https://github.com/Lu-source/MultiwayAnalysis-DynamicMetabolomicsData .
Notlar
- Glikoliz modelindeki reaksiyonlar çok hızlıdır ve metabolitlerin konsantrasyonları sabit duruma hızla ulaşır. Bu nedenle, dinamik değişimin ortaya çıktığı kısa bir zaman aralığına odaklanıyoruz. Ancak, böyle bir zaman ölçeğinde gerçek metabolomik verileri edinmek mümkündür; hücre içi metabolitleri çıkarırken örnekleme süresinin örnek başına 220 ms olabileceği [ 29 ]’a bakın.
- Kolesterol modelinde zaman birimi gündür ve [ 5 ]’ teki deneyde zaman aralığı, sistemin kararlı durumuna ulaşabilmesi için yeterince uzun olacak şekilde ayarlanmıştır.
- MATLAB gösteriminde: tspan=logspace(0,6,1000)-1 vektörünü ele alalım; seçilen zaman noktaları tspan(1:24:500)’dir.
- Küçük biyolojik varyasyonlara sahip sistemleri taklit etmek için küçük sayılar seçiyoruz, ancak bu sayı, makalede daha sonra tartışılacağı üzere büyük de olabilir.
- Bu kısıtlamalar doğrusal açık sistemlerde kütle korunum yasasının sağlanması için veri üretiminde her zaman kullanılır.
- Burada, VmaxPFK dışındaki enzimler de düşünülebilir. Yolun orta kısmında konumlanmış bir enzimle başlamak istediğimiz için VmaxPFK’yi seçiyoruz.
- İndüklenen varyasyon diğer enzim reaksiyon hızlarındaki azalmayla, örneğin VmaxPYK / mutant6 / mutant10’un %50 azalmasıyla tanımlanıyorsa , anormal denekler sırasıyla abnormal_VmaxPYK / abnormal_mutant6 / abnormal_mutant10 olarak gösterilir .
- Bir CP modelinin çekirdek dizisi, CP modelini Tucker3 modelinin özel bir durumu olarak ifade ederek elde edilen çekirdek tensörüdür. CP modelinin çekirdek dizisi, , yani, rütbe bir bileşenlerinin ağırlıkları, süperdiyagonalde ve diğer tüm girişler sıfır olan bir süperdiyagonal tensördür.λ
- https://github.com/stephenbeckr/L-BFGS-BC adresinde bulunan LBFGS-B uygulamasını kullanıyoruz .
- Paralind modeli için http://www.models.life.ku.dk/paralind adresindeki uygulamayı kullanıyoruz .
- VmaxPYK reaksiyon hızının azalması, VmaxPFK’nin azalmasından ve bunun sonucunda FBP’nin azalmasından ve ileri beslemeli kontrol döngüsünün etkisinden kaynaklanmaktadır.
Referanslar
- Pellis L, van Erk MJ, van Ommen B, Bakker GC, Hendriks HF, Cnubben NH, Kleemann R, van Someren EP, Bobeldijk I, Rubingh CM, ve diğerleri. Yemek sonrası bir meydan okumadan sonra plazma metabolomikleri ve proteomik profillemesi, insan metabolik durumu üzerinde ince diyet etkilerini ortaya koymaktadır. Metabolomik. 2012;8(2):347–59.Madde CAS Google Akademik
- van Duynhoven J, Vaughan EE, Jacobs DM, Kemperman RA, van Velzen EJ, Gross G, Roger LC, Possemiers S, Smilde AK, Doré J, ve diğerleri. İnsan süperorganizmasındaki polifenollerin metabolik kaderi. Proc Natl Acad Sci. 2011;108(Ek 1):4531–8.Madde Google Akademik
- Price ND, Magis AT, Earls JC, Glusman G, Levy R, Lausted C, McDonald DT, Kusebauch U, Moss CL, Zhou Y, ve diğerleri. Kişisel, yoğun, dinamik veri bulutları kullanan 108 bireyden oluşan bir sağlık çalışması. Nat Biotechnol. 2017;35(8):747.Madde CAS Google Akademik
- Lin Z, Zhang Q, Dai S, Gao X. Grup ve nükleer norm düzenlenmiş çok değişkenli regresyon yoluyla uzunlamasına hedefsiz metabolomik verilerde zamansal kalıpların keşfi. Metabolitler. 2020;10(1):33.Madde CAS Google Akademik
- van de Pas NC, Woutersen RA, van Ommen B, Rietjens IM, de Graaf AA. İnsanlarda plazma kolesterol konsantrasyonlarını tahmin eden fizyolojik temelli bir siliko kinetik modeli. J Dudak Res. 2012;53(12):2734–46.Madde Google Akademik
- Adamko D, Rowe BH, Marrie T, Sykes BD, ve diğerleri. Normal insan idrarındaki metabolitlerin değişimi. Metabolomik. 2007;3(4):439–51.Madde Google Akademik
- Van Batenburg MF, Coulier L, van Eeuwijk F, Smilde AK, Westerhuis JA. Kapsamlı fonksiyonel genomik veriler için yeni değerler: metabolomik durum. Anal Kimya 2011;83(9):3267–74.Madde Google Akademik
- Smilde A, Westerhuis J, Hoefsloot H, Bijlsma S, Rubingh C, Vis D, Jellema R, Pijl H, Roelfsema F, Van Der Greef J. Dinamik metabolomik veri analizi: öğretici bir inceleme. Metabolomik. 2010;6(1):3–17.Madde CAS Google Akademik
- Yamamoto H, Yamaji H, Abe Y, Harada K, Waluyo D, Fukusaki E, Kondo A, Ohno H, Fukuda H. Gizli değişkenlere farklı cezalar veren pca, pls, opls ve rfda kullanılarak metabolom verileri için boyutsallık indirgeme. Chemom Intell Lab Syst. 2009;98(2):136–42.Madde CAS Google Akademik
- Nyamundanda G, Gormley IC, Brennan L. Uzunlamasına metabolomik verilerin analizi için dinamik olasılıklı ana bileşenler modeli. JR Stat Soc Ser C Appl Stat. 2014;63(5):763–82.Madde Google Akademik
- Smilde A, Bro R, Geladi P. Çok yönlü analiz: kimyasal bilimlerdeki uygulamalar. Chichester: Wiley; 2004.Kitap Google Akademik
- Acar E, Yener B. Gözetimsiz çok yönlü veri analizi: bir literatür taraması. IEEE Trans Knowl Data Eng. 2009;21(1):6–20.Madde Google Akademik
- Kolda TG, Bader BW. Tensör ayrıştırmaları ve uygulamaları. SIAM Rev. 2009;51(3):455–500.Madde Google Akademik
- Papalexakis EE, Faloutsos C, Sidiropoulos ND. Veri madenciliği ve veri füzyonu için tensörler: modeller, uygulamalar ve ölçeklenebilir algoritmalar. ACM Trans Intell Syst Technol. 2016;8(2):16.Google Akademik
- Bader BW, Berry MW, Browne M. PARAFAC kullanılarak Enron e-postasında tartışma takibi. Londra: Springer; 2008. s. 147–63.
- Dunlavy DM, Kolda TG, Acar E. Matris ve tensör faktörizasyonlarını kullanarak zamansal bağlantı tahmini. ACM TKDD. 2011;5(2):10.Google Akademik
- Sun J, Papadimitriou S, Philip SY. Yüksek boyutlu ve çok yönlü akışlarda pencere tabanlı tensör analizi. Veri madenciliği üzerine altıncı uluslararası konferansta (ICDM’06). IEEE; 2006. s. 1076–80.
- Acar E, Aykut-Bingol C, Bingol H, Bro R, Yener B. Epilepsi tensörlerinin çok yönlü analizi. Biyoenformatik. 2007;23(13):10–8.Madde Google Akademik
- Davidson I, Gilpin S, Carmichael O, Walker P. fMRI verilerinin kısıtlanmış tensör analizi yoluyla ağ keşfi. KDD’13: 19. ACM SIGKDD bilgi keşfi ve veri madenciliği uluslararası konferansının bildirileri. ACM; 2013. s. 194–202.
- Roald M, Bhinge S, Jia C, Calhoun V, Adali T, Acar E. Parafac2 modelini kullanarak ağ evriminin izlenmesi. In: ICASSP’20: 45. IEEE akustik, konuşma ve sinyal işleme uluslararası konferansının bildirileri; 2020.
- Yin K, Afshar A, Ho JC, Cheung WK, Zhang C, Sun J. Logpar: eksik değerlere sahip zamansal ikili veriler için lojistik parafac2 çarpanlarına ayırma. In: KDD’20: 26. ACM SIGKDD bilgi keşfi ve veri madenciliği uluslararası konferansının bildirileri; 2020.
- Harshman RA. PARAFAC prosedürünün temelleri: “açıklayıcı” çok modlu faktör analizi için modeller ve koşullar. UCLA Work Pap Phonet. 1970;16:1–84.
- Carroll JD, Chang JJ. “Eckart-young” ayrıştırmasının n-yollu genellemesi yoluyla çok boyutlu ölçeklemedeki bireysel farklılıkların analizi. Psychometrika. 1970;35:283–319.
- Jansen JJ, Bro R, Hoefsloot HC, van den Berg FW, Westerhuis JA, Smilde AK. Parafasca: Asca, metabolik parmak izi verilerinin analizi için parafac ile birleştirildi. J Kemom. 2008;22(2):114–21.Madde CAS Google Akademik
- van Heerden JH, Wortel MT, Bruggeman FJ, Heijnen JJ, Bollen YJ, Planqué R, Hulshof J, O’Toole TG, Wahl SA, Teusink B. Geçişte kayıp: glikolizin başlatılması, büyümeyen hücrelerin alt popülasyonlarını verir. Bilim. 2014;343:6174.
- Tucker LR. Üç modlu faktör analizi üzerine bazı matematiksel notlar. Psychometrika. 1966;31(3):279–311.Madde CAS Google Akademik
- Kruskal JB. Üç yollu diziler: üç doğrusal ayrıştırmaların sıralaması ve benzersizliği, aritmetik karmaşıklık ve istatistiklere uygulama. Doğrusal Cebir Uygulaması 1977;18(2):95–138.Madde Google Akademik
- Bro R, Harshman RA, Sidiropoulos ND, Lundy ME. Doğrusal olarak bağımlı yüklemelerle çok yönlü verilerin modellenmesi. J Chemom. 2009;23(7–8):324–40.Madde CAS Google Akademik
- Schaefer U, Boos W, Takors R, Weuster-Botz D. Hücre içi metabolit dinamiklerini izlemek için otomatik örnekleme cihazı. Anal Biochem. 1999;270(1):88–96.Madde CAS Google Akademik
- Hitchcock FL. Bir tensörün veya poliadiğin ürünlerin toplamı olarak ifadesi. J Math Phys. 1927;6(1–4):164–89.Madde Google Akademik
- Acar E, Dunlavy DM, Kolda TG, Mørup M. Eksik veriler için ölçeklenebilir tensör faktörizasyonları. Chemom Intell Lab Syst. 2011;106(1):41–56.Madde CAS Google Akademik
- Tomasi G, Bro R. Parafac ve eksik değerler. Chemom Intell Lab Syst. 2005;75(2):163–80.Madde CAS Google Akademik
- Kiers HA, Smilde AK. İkinci dereceden enstrümantal verilerle parametre tahmini için bir araç olarak kısıtlanmış üç modlu faktör analizi. J Chemom. 1998;12(2):125–47.Madde CAS Google Akademik
- Bro R, Smilde AK. Bileşen analizinde merkezleme ve ölçekleme. J Chemom. 2003;17(1):16–33.Madde CAS Google Akademik
- Bro R, Kiers HA. Parafak modellerindeki bileşen sayısını belirlemek için yeni ve etkili bir yöntem. J Chemom. 2003;17(5):274–86.Madde CAS Google Akademik
- Stegeman A. Candecomp/parafac ve indscal’daki dejenerasyon, iki değerli tipik bir sıralamaya sahip birkaç üç dilimli dizi için açıklandı. Psychometrika. 2007;72(4):601–19.Madde Google Akademik
- Bro R. Parafac öğretici ve uygulamaları. Chemom Intell Lab Syst. 1997;38(2):149–72.Madde CAS Google Akademik
- Acar E, Dunlavy DM, Kolda TG. Kanonik tensör ayrıştırmalarına uyum sağlamak için ölçeklenebilir bir optimizasyon yaklaşımı. J Chemom. 2011;25(2):67–86.Madde CAS Google Akademik
- Bader BW, Kolda TG, ve diğerleri. Genel yazılım, son sürüm. MATLAB için Tensor Toolbox, Sürüm 3.1.
- Andersson CA, Bro R. Matlab için n-yollu araç kutusu. Chemom Intell Lab Syst. 2000;52(1):1–4.Madde CAS Google Akademik
- Wopereis S, Stroeve JH, Stafleu A, Bakker GC, Burggraaf J, van Erk MJ, Pellis L, Boessen R, Kardinaal AA, van Ommen B. Sağlıklı ve tip 2 diyabetik deneklerde standartlaştırılmış karışık yemek tolerans testinin çok parametreli karşılaştırması : phenflex mücadelesi. Genler Nutr. 2017;12(1):1–14.Madde Google Akademik
- Harshman RA. PARAFAC2: matematiksel ve teknik notlar. UCLA Çalışma Pap Phonet. 1972;22:30–47.Google Akademik
- Bro R, Andersson CA. Çok yönlü algoritmaların hızının artırılması: Bölüm II: sıkıştırma. Chemom Intell Lab Syst. 1998;42(1–2):105–13.Madde CAS Google Akademik
- Beutel A, Talukdar PP, Kumar A, Faloutsos C, Papalexakis EE, Xing EP. Flexifact: Hadoop’ta bağlı tensörlerin ölçeklenebilir esnek faktörizasyonu. In: 2014 SIAM uluslararası veri madenciliği konferansı bildirileri; 2014.
- Jendoubi T, Ebbels TMD. Zaman seyri metabolik verilerinin ve biyobelirteç keşfinin bütünleştirici analizi. BMC Bioinform. 2020;21:11.Madde Google Akademik
- Acar E, Bro R, Smilde AK. Eşleştirilmiş matris ve tensör faktörizasyonlarını kullanarak metabolomikte veri birleştirme. IEEE Bildirileri. 2015;103:1602–20.Madde CAS Google Akademik
Teşekkürler
Amsterdam Üniversitesi Swammerdam Yaşam Bilimleri Enstitüsü’nden Dr. Meike T. Wortel’e, maya glikoliz modeli hakkındaki birçok yararlı iletişimi ve içgörüsü için teşekkür etmek istiyoruz. Ayrıca, Danimarka Pediatrik Astım Merkezi’ndeki (COPSAC) Dr. Morten Arendt Rasmussen ve işbirlikçilerimize de yararlı tartışmalar için minnettarız. Ayrıca, makalemizi iyileştirmemize yardımcı olan değerli yorumları için değerlendiricilere de minnettarız.
Finansman
Bu makalede sunulan çalışma Novo Nordisk Vakfı Hibe NNF19OC0057934 ve Norveç Araştırma Konseyi proje #300489 tarafından desteklenmiştir.
Alıntı Yapılan Kaynak: https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04550-5